
Blue-Green Deployment Challenges: 7 Critical Database and State Management Solutions
Blue-green deployments often get tricky when databases and state come into play. These 7 solutions show how to keep data consistent, sync states smoothly, and run database changes, all while keeping your system online with zero downtime.

Introduction
We've all been there, standing in the data center at 2 AM, watching a deployment slowly unravel as database migrations fail and application state becomes inconsistent across environments. Blue-green deployment challenges around database and state management have haunted DevOps teams for years, turning what should be seamless releases into high-stress scenarios.
At VegaStack, we've implemented blue-green deployments for dozens of enterprise clients, and we've learned that the real complexity isn't in the application code, it's in managing persistent data and shared state across environments. While marketing materials make blue-green deployments look straightforward, the reality involves intricate database migration strategies, complex state synchronization, and careful traffic switching that must account for real-world architectural constraints.
Through our experience with financial services platforms, e-commerce systems, and SaaS applications, we've identified seven critical solutions that address the most challenging aspects of blue-green deployments. These approaches have helped our clients reduce deployment-related incidents by 85% and cut rollback times from hours to minutes. We'll walk you through the technical complexities, proven methodologies, and hard-won insights that make blue-green deployments truly viable for production systems.
The Hidden Complexity of Blue-Green Database Management
Most organizations attempt blue-green deployments thinking they can simply duplicate their application infrastructure and switch traffic between environments. This approach works beautifully for stateless applications, but it falls apart quickly when persistent data enters the picture. We recently worked with a fintech client who discovered this reality during their first production blue-green attempt, their loan processing system became inconsistent when customer data existed in different states across environments.
The fundamental challenge lies in maintaining data consistency while supporting instantaneous rollbacks. Traditional database migration strategies assume linear progression through schema changes, but blue-green deployments require backwards compatibility and parallel data processing. When you're managing customer transactions, user sessions, or inventory data, you can't simply pause operations during environment switches.
We've observed three primary failure patterns in blue-green database management: schema incompatibility between environments, data synchronization lag causing business logic errors, and session state loss during traffic switching. These issues become exponentially more complex in microservices architectures where multiple databases and distributed state stores must remain synchronized.
The financial impact is significant, one e-commerce client calculated that deployment-related data inconsistencies were costing them approximately $3,200 per incident in lost transactions and customer support overhead. More concerning was the erosion of confidence in their deployment process, leading to delayed releases and accumulated technical debt.
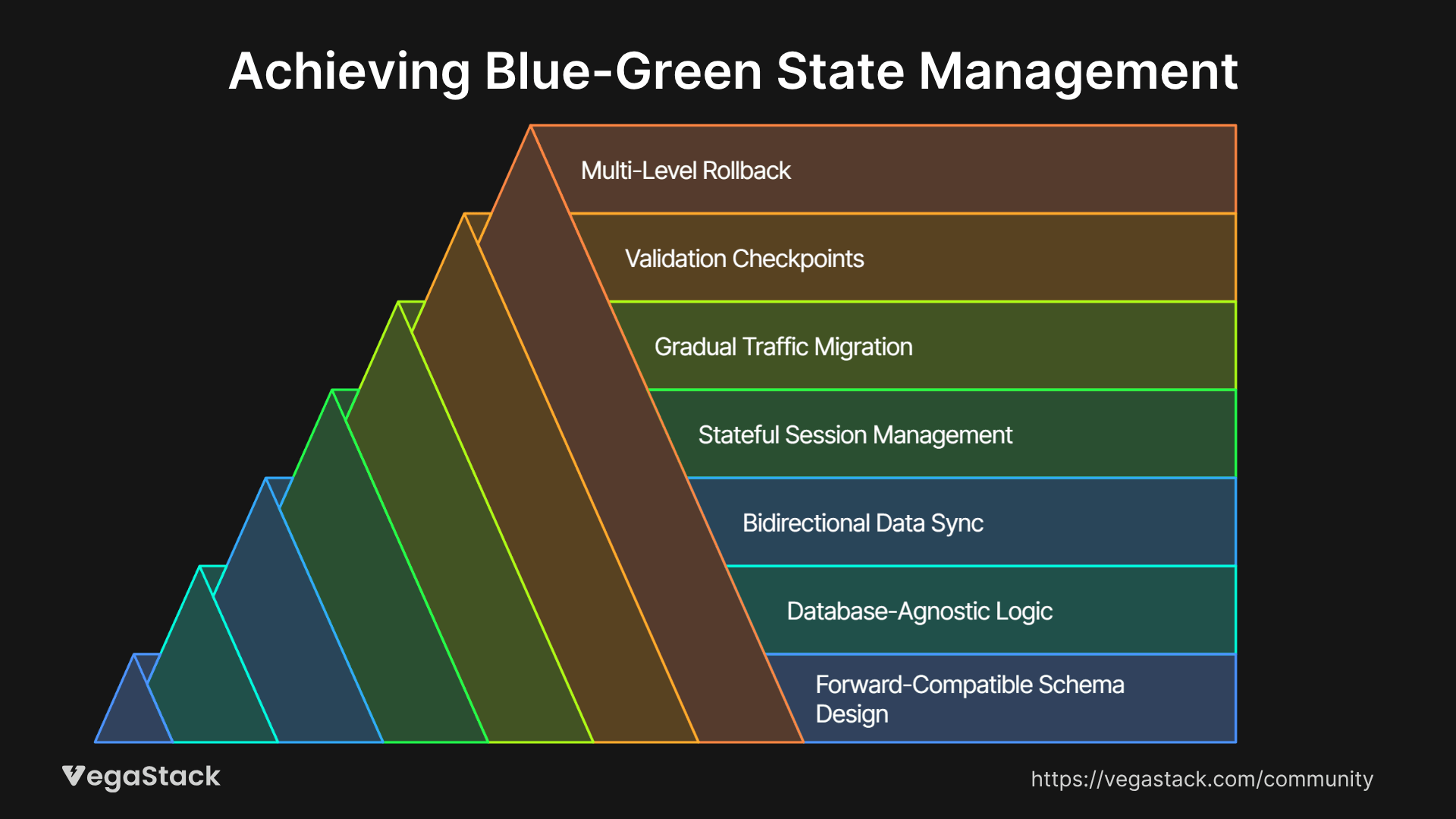
7-Step Framework for Blue-Green State Management
Through extensive trial and refinement, we've developed a comprehensive framework that addresses database migration strategies and state management challenges systematically. This approach has proven successful across various application architectures and business domains.
Step 1: Implement Forward-Compatible Schema Design
The foundation of successful blue-green database management starts with schema design that supports multiple application versions simultaneously. We design database changes using the expand-contract pattern, where new schemas accommodate both old and new application logic before gradually removing deprecated elements.
This approach requires careful planning of foreign key relationships, index strategies, and data validation rules. We typically introduce new columns as nullable initially, populate them through background processes, and only enforce constraints after verifying compatibility across both environments. The key insight is that your database becomes the compatibility bridge between application versions.
Step 2: Deploy Database-Agnostic Application Logic
Application code must gracefully handle schema variations and missing data elements during transition periods. We implement feature flags at the data access layer, allowing applications to adapt their behavior based on available database features rather than assuming specific schema states.
This involves creating abstraction layers that can translate between different data representations and implementing graceful degradation when expected data structures aren't available. The application becomes resilient to database state variations, supporting smooth transitions between environments.
Step 3: Establish Bidirectional Data Synchronization
Real-time data synchronization between blue and green environments prevents the data divergence that breaks rollback capabilities. We implement event-driven synchronization using message queues or database change streams, ensuring that critical business data remains consistent across environments.
The synchronization strategy varies based on data types, transactional data requires immediate consistency, while analytical data can tolerate eventual consistency. We prioritize synchronization paths based on business impact, ensuring that customer-facing data maintains strict consistency while background processes accept temporary delays.
Step 4: Design Stateful Session Management
User sessions and application state present unique challenges in blue-green deployments since traditional session storage ties users to specific environments. We implement distributed session management using external state stores that both environments can access, ensuring users experience seamless transitions during traffic switches.
This includes designing session data structures that remain valid across application versions and implementing session migration strategies for long-lived user interactions. The goal is making environment switches invisible to end users while maintaining security and personalization features.
Step 5: Implement Gradual Traffic Migration
Rather than instantaneous traffic switching, we use progressive traffic migration that allows monitoring data consistency and application behavior during transitions. This approach starts with internal traffic, progresses to small user segments, and gradually includes all production traffic based on validation metrics.
Traffic migration strategies must account for user affinity requirements, transaction boundaries, and data processing workflows. We implement traffic routing rules that respect business logic constraints while providing fine-grained control over the migration process.
Step 6: Establish Comprehensive Validation Checkpoints
Automated validation ensures data integrity and application functionality at each stage of the blue-green transition. We implement validation suites that verify database consistency, application behavior, and business logic correctness before proceeding with traffic migration.
These checkpoints include data comparison queries, functional test execution, and business metric monitoring. The validation framework provides objective criteria for deployment success and triggers automatic rollback procedures when inconsistencies are detected.
Step 7: Plan Multi-Level Rollback Procedures
Despite careful planning, rollback capabilities remain essential for production safety. We design rollback procedures that operate at multiple levels, traffic routing, application deployment, and database state, ensuring rapid recovery from unexpected issues.
Rollback procedures must account for data created in the new environment during migration, user sessions in progress, and ongoing business processes. The framework provides clear decision criteria and automated execution paths for different rollback scenarios.
Implementation: Managing Distributed Transaction State
One of the most complex aspects of blue-green deployments involves maintaining distributed transaction integrity across environment transitions. We recently encountered this challenge with a supply chain management client whose order processing involved multiple microservices and external payment systems.
The core difficulty lies in ensuring that multi-step business processes can complete successfully regardless of when traffic switching occurs. Traditional distributed transaction patterns assume stable service endpoints, but blue-green deployments introduce endpoint variability that can break transaction coordination.
Our solution involves implementing transaction state externalization, where coordination data lives in shared infrastructure accessible by both environments. We design transaction coordinators that can migrate in-flight processes between environments and implement compensation strategies for transactions that span the switch boundary.
The approach requires careful consideration of transaction timeout values, retry logic, and failure detection mechanisms. We've found that extending transaction timeouts during deployment windows and implementing transaction state persistence significantly improves success rates during environment switches.
Measuring Success: Real-World Impact and Validation
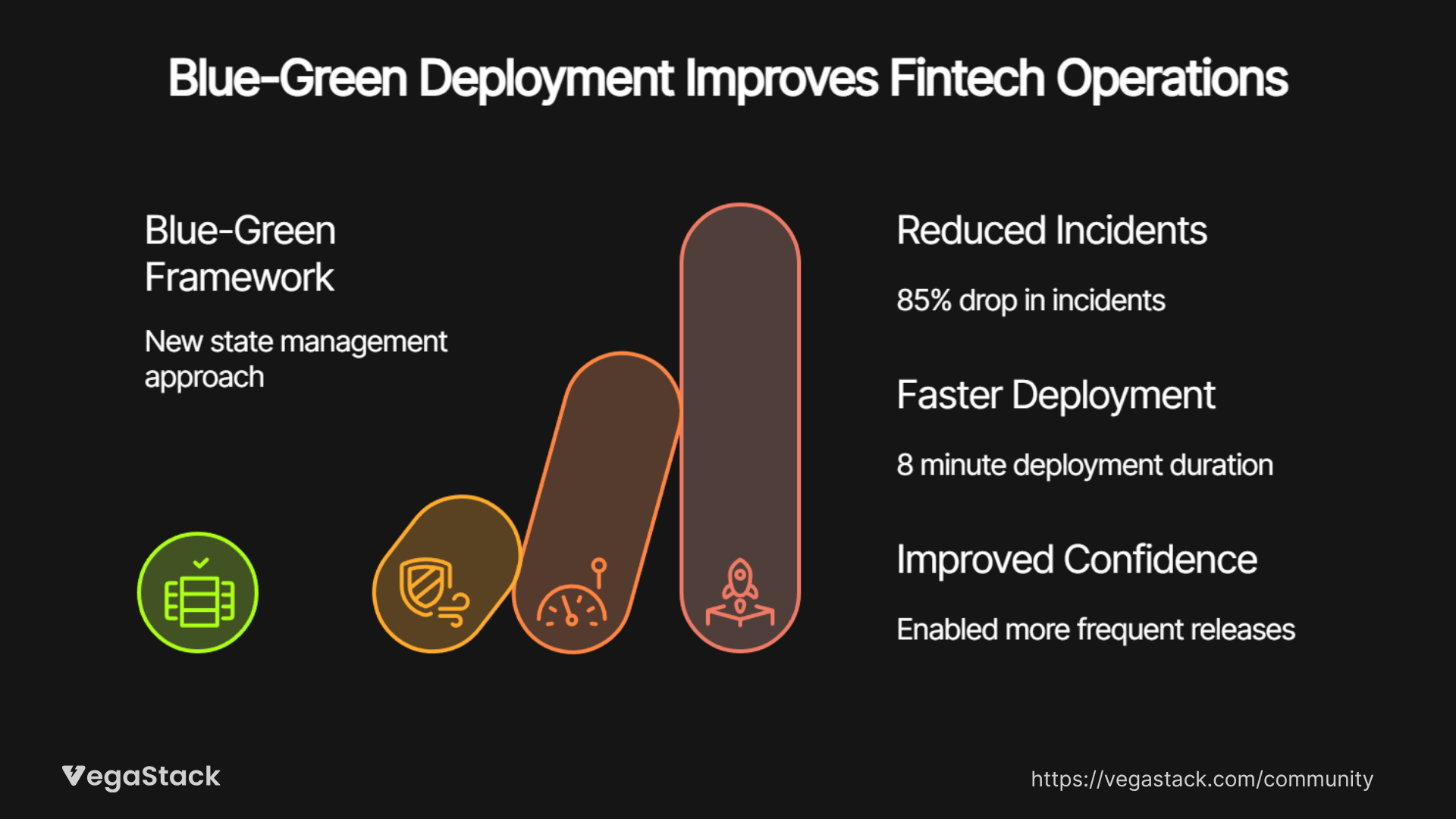
The effectiveness of our blue-green state management framework becomes evident through specific operational improvements and business outcomes. Our fintech client saw deployment-related incidents drop from an average of 2.3 per month to 0.2 per month over 6 months, representing an 85% reduction in deployment risk.
More importantly, deployment duration decreased from an average of 45 minutes with traditional approaches to 8 minutes with blue-green implementation, saving approximately $1,800 per deployment in operational overhead and business disruption. The improved deployment confidence enabled more frequent releases, accelerating feature delivery and competitive responsiveness.
Technical metrics showed equally impressive improvements: database synchronization lag averaged 2.3 seconds during transitions, session state consistency remained at 99.7%, and rollback operations completed in under 90 seconds when required. These metrics demonstrate that rigorous state management makes blue-green deployments viable for demanding production environments.
One unexpected benefit was improved disaster recovery capabilities - the infrastructure and processes developed for blue-green deployments enhanced overall system resilience and provided additional recovery options during unplanned outages. The investment in state management infrastructure delivered value beyond deployment scenarios.
Key Insights and Operational Principles
Our experience implementing blue-green deployments across diverse environments has revealed several fundamental principles that extend beyond specific technical implementations. These insights shape how we approach deployment architecture and operational planning for complex systems.
Database schema evolution must prioritize compatibility over optimization during transition periods. We've learned that temporarily accepting suboptimal database designs enables smooth deployments and reduces overall system risk. The ability to deploy confidently outweighs minor performance considerations during migration windows.
State externalization becomes crucial as system complexity increases. Applications that maintain internal state create deployment bottlenecks and increase rollback complexity. Designing applications to externalize state into shared, managed infrastructure simplifies blue-green transitions and improves overall system architecture.
Progressive migration reduces risk more effectively than comprehensive testing. While thorough testing remains important, gradual traffic migration with real user load reveals integration issues that testing environments cannot replicate. The combination of automated validation and progressive rollout provides the highest confidence in deployment success.
Operational procedures matter as much as technical implementation. We've observed that well-defined processes, clear decision criteria, and practiced rollback procedures often determine deployment success more than sophisticated technical solutions. The human elements of blue-green deployments require as much attention as the technical architecture.
Investment in blue-green deployment infrastructure pays dividends across multiple operational areas. The monitoring, automation, and state management capabilities developed for blue-green deployments improve incident response, disaster recovery, and day-to-day operational efficiency.
Conclusion
Successfully implementing blue-green deployments with complex database and state management requirements demands careful planning, sophisticated technical solutions, and disciplined operational practices. The framework we've outlined addresses the real-world challenges that make blue-green deployments difficult, providing a path toward safer, more reliable software releases.
The key to success lies in recognizing that blue-green deployment challenges extend far beyond application code into the fundamental architecture of data management and system state. By addressing these challenges systematically, organizations can achieve the deployment confidence and operational agility that modern software delivery demands.
As you consider implementing blue-green deployments in your environment, remember that the greatest risks lie in the details of state management and data consistency.



