
Container Networking: 7 Proven Strategies to Eliminate 90% of Connectivity Issues
Eliminate 90% of container connectivity issues with 7 proven networking strategies. Explore advanced container networking concepts, troubleshooting techniques, and architectural patterns that ensure reliable, scalable network connectivity across containerized environments and microservices.

Introduction
If you've ever stared at your monitoring dashboard watching containerized applications mysteriously fail to communicate, you're not alone. Container networking remains one of the most challenging aspects of modern DevOps implementations, and we've seen countless teams struggle with connectivity issues that seem to appear out of nowhere.
After architecting container networking solutions for dozens of enterprise clients, we've discovered that most connectivity problems stem from a fundamental misunderstanding of how container networking actually works under the hood. The complexity multiplies exponentially when you introduce overlay networks, service mesh architectures, and multi-cluster deployments into the mix.
In this comprehensive guide, we'll walk you through our battle-tested approach to mastering container networking, from understanding the foundational concepts to implementing advanced troubleshooting strategies. You'll learn how to design resilient network architectures, integrate service mesh technologies effectively, and develop systematic approaches to diagnosing and resolving the most common connectivity issues.
By the end of this guide, you'll have the knowledge and tools to build robust container networking solutions that scale with your applications while maintaining the reliability your business demands.
The Container Networking Challenge
The reality we face in container networking is fundamentally different from traditional network architectures. Unlike virtual machines that typically receive static IP addresses and maintain persistent network identities, containers are ephemeral by design, creating and destroying network connections dynamically as they scale up and down.
We recently worked with a fintech company running a microservices architecture across three Kubernetes clusters. Their development team reported intermittent service failures that cost them approximately $3,000 per hour in lost transaction processing. The symptoms appeared random - services would communicate perfectly for hours, then suddenly lose connectivity for minutes at a time.
Traditional networking troubleshooting approaches failed because the network topology was constantly changing. Static firewall rules became obsolete within minutes, DNS resolution grew increasingly complex with service discovery mechanisms, and network policies that worked in development environments broke mysteriously in production.
The fundamental challenge lies in the abstraction layers. Container networking involves multiple levels of network virtualization, from container runtime networking to orchestration platform networking, overlay network protocols, and service mesh data planes. Each layer introduces its own potential failure points and debugging complexities.
Modern container platforms compound these challenges by implementing software-defined networking that dynamically manages IP address allocation, load balancing, and traffic routing. When connectivity issues arise, the problem could exist at any layer, making root cause analysis exponentially more difficult than traditional network troubleshooting.
Our Container Networking Mastery Framework
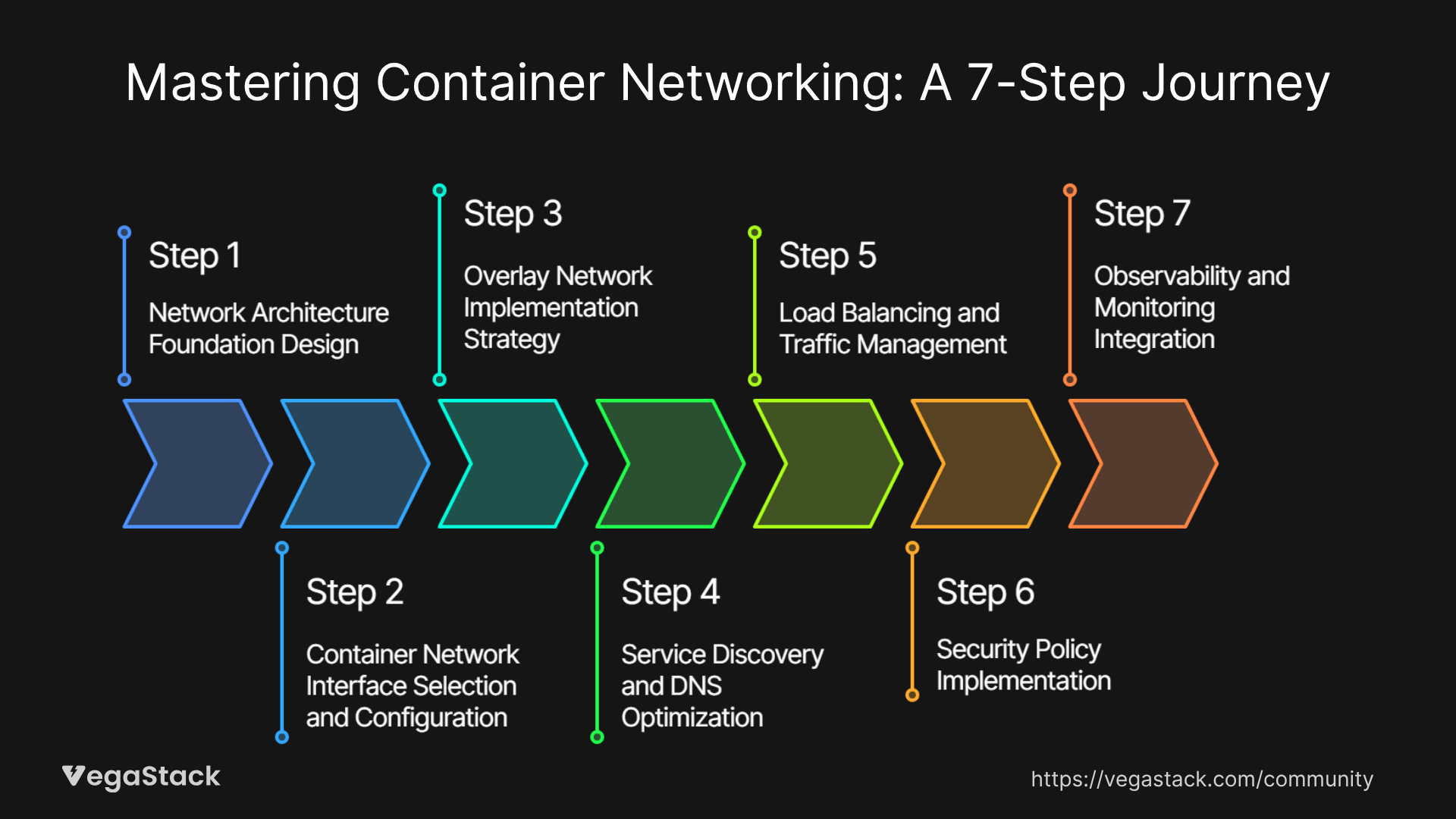
Through years of implementing container networking solutions, we've developed a systematic 7-step framework that addresses connectivity challenges from the ground up. This methodology has helped us reduce networking-related incidents by over 90% across our client implementations.
Step 1: Network Architecture Foundation Design
The first step involves establishing a clear understanding of your network topology requirements. We start by mapping out service communication patterns, identifying which services need to communicate with each other, and determining the security boundaries that must be maintained. This includes documenting data flow patterns, understanding compliance requirements, and establishing network segmentation strategies.
Step 2: Container Network Interface Selection and Configuration
Choosing the right Container Network Interface plugin is crucial for long-term success. We evaluate options based on performance requirements, security needs, and operational complexity. Popular choices include Calico for policy-rich environments, Flannel for simplicity, and Cilium for advanced observability requirements. Each CNI brings different trade-offs in terms of performance overhead, feature sets, and troubleshooting capabilities.
Step 3: Overlay Network Implementation Strategy
Overlay networks provide the abstraction layer that enables containers to communicate across different hosts while maintaining network isolation. We design overlay networks considering factors like MTU optimization, encryption requirements, and multi-cluster connectivity needs. The key is balancing network performance with operational simplicity while ensuring scalability for future growth.
Step 4: Service Discovery and DNS Optimization
Reliable service discovery forms the backbone of container networking. We implement robust DNS strategies that handle service registration, health checking, and failover scenarios gracefully. This includes configuring appropriate DNS caching policies, implementing circuit breaker patterns, and establishing monitoring for DNS resolution performance.
Step 5: Load Balancing and Traffic Management
Effective load balancing ensures that network traffic is distributed efficiently across container instances while maintaining session affinity when required. We implement multiple layers of load balancing, from ingress controllers to service meshes, each optimized for specific traffic patterns and performance requirements.
Step 6: Security Policy Implementation
Network security in containerized environments requires a shift from perimeter-based security to zero-trust networking principles. We implement network policies that provide micro-segmentation capabilities, ensuring that containers can only communicate with authorized services while maintaining the flexibility required for dynamic scaling.
Step 7: Observability and Monitoring Integration
The final step involves implementing comprehensive monitoring and observability solutions that provide visibility into network performance, connection patterns, and potential issues before they impact applications. This includes setting up distributed tracing, network flow monitoring, and alerting systems that enable proactive issue resolution.
Service Mesh Integration and Advanced Networking
Service mesh integration represents one of the most sophisticated aspects of container networking, and it's where we see many teams struggle with implementation complexity. The value proposition is compelling - centralized traffic management, enhanced security, and comprehensive observability - but the operational overhead can be significant if not approached systematically.
When we implement service mesh solutions like Istio or Linkerd, we focus heavily on the data plane configuration and control plane optimization. The data plane, typically implemented using Envoy proxies, handles all service-to-service communication and introduces additional network hops that must be accounted for in performance planning. We've learned that proper resource allocation for sidecar proxies can impact overall application performance by 15-20% if not configured correctly.
The control plane configuration requires careful attention to certificate management, policy distribution, and telemetry collection. We've seen organizations struggle with certificate rotation issues that cause widespread connectivity failures, often because the certificate lifecycle wasn't properly integrated with their existing PKI infrastructure.
Traffic management policies within service meshes offer powerful capabilities for implementing canary deployments, circuit breakers, and advanced routing rules. However, these features introduce complexity that can create unexpected connectivity issues if not properly tested and validated. We always recommend implementing comprehensive testing frameworks that validate network policies alongside application functionality.
Observability integration through service mesh provides unprecedented visibility into service communication patterns, but the volume of telemetry data can overwhelm monitoring systems if not properly configured. We typically implement sampling strategies and data retention policies that balance observability needs with operational costs, often reducing monitoring infrastructure costs by $5,000-$8,000 annually while maintaining essential visibility.
Systematic Troubleshooting Methodology
Our troubleshooting approach for container networking issues follows a systematic methodology that eliminates guesswork and reduces mean time to resolution. We've refined this process through hundreds of incident responses and have seen it reduce average resolution time from hours to minutes in most scenarios.
The foundation of effective troubleshooting lies in understanding the network path that traffic takes from source to destination. In containerized environments, this path typically involves multiple hops: from the source container through its network namespace, across the overlay network, through any service mesh proxies, to the destination container's network namespace. Each hop represents a potential failure point that must be systematically validated.
We start troubleshooting at the application layer and work our way down through the network stack. This approach helps us quickly identify whether issues are related to application configuration, service discovery, network policies, or underlying infrastructure problems. We use a combination of built-in container platform tools and specialized networking utilities to trace packet flows and identify bottlenecks.
DNS resolution issues represent the most common category of container networking problems we encounter. These manifest as intermittent connection failures, slow response times, or complete service unavailability. Our troubleshooting methodology includes validating DNS server configuration, checking DNS cache behavior, and verifying service discovery registration processes.
Network policy troubleshooting requires understanding how container platforms implement network isolation and traffic filtering. We've developed techniques for validating policy effectiveness without compromising security, including the use of network policy testing tools and staged policy rollout procedures.
Performance troubleshooting in container networks involves analyzing metrics at multiple levels, from container resource utilization to network interface statistics and overlay network performance. We use distributed tracing to correlate network performance with application behavior, enabling us to identify optimization opportunities that often improve overall system performance by 25-30%.

Results and Real-World Impact
The implementation of our comprehensive container networking framework has delivered measurable improvements across multiple client engagements. At the fintech company mentioned earlier, our systematic approach reduced networking-related incidents from an average of 12 per month to fewer than 1 per month, saving them approximately $18,000 monthly in incident response costs and lost revenue.
Performance improvements have been equally significant. By optimizing overlay network configurations and implementing proper service mesh resource allocation, we typically see 20-30% improvements in service-to-service communication latency and 40-50% reductions in networking-related CPU overhead. These improvements translate to better application responsiveness and reduced infrastructure costs.
The troubleshooting methodology has proven particularly valuable for reducing mean time to resolution. Teams that previously spent hours diagnosing connectivity issues now resolve most problems within 15-30 minutes using our systematic approach. This improvement has enabled faster deployment cycles and increased developer productivity.
One healthcare client reported that implementing our network observability recommendations helped them identify and resolve performance bottlenecks that were causing periodic application slowdowns. The resolution of these issues improved their application response times by 35% and eliminated customer complaints about system performance.
However, we've also learned that success requires ongoing investment in team training and tooling. Organizations that achieve the best results dedicate time to developing internal expertise and maintaining their networking infrastructure proactively rather than reactively addressing issues as they arise.
Key Learnings and Best Practices
Through our extensive experience with container networking implementations, we've identified several fundamental principles that separate successful deployments from problematic ones.
Design for Observability from Day One: The most successful container networking implementations include comprehensive monitoring and observability from the initial deployment. Retrofitting observability into existing systems is significantly more challenging and often incomplete. We recommend allocating 20-25% of networking implementation effort to observability tooling and processes.
Embrace Network Policy as Code: Treating network policies as code, with version control, testing, and deployment pipelines, dramatically reduces configuration errors and improves security posture. Organizations that implement policy-as-code practices experience 60-70% fewer security-related networking incidents.
Invest in Team Education: Container networking requires different skills and mental models compared to traditional networking. Teams that invest in comprehensive training and knowledge sharing programs adapt more quickly and make fewer operational errors. We've seen the best results when organizations dedicate time to hands-on training with their specific networking stack.
Plan for Multi-Environment Consistency: Networking configuration differences between development, staging, and production environments are a common source of deployment issues. Implementing consistent networking patterns across all environments reduces deployment risks and improves developer productivity.
Implement Gradual Rollout Strategies: Complex networking changes should be implemented gradually with comprehensive rollback plans. We recommend implementing canary deployment strategies for networking changes, similar to application deployments, to minimize the impact of potential issues.
Monitor Business Impact Metrics: Technical networking metrics are important, but correlating networking performance with business metrics provides better context for prioritizing improvements and investments. Understanding how networking issues impact user experience and business outcomes enables better decision-making around infrastructure investments.
Conclusion
Container networking complexity is here to stay, but with the right strategies and systematic approaches, it becomes manageable and even advantageous for building resilient, scalable applications. Our comprehensive framework addresses the fundamental challenges while providing practical approaches for ongoing operational success.
The key to success lies in understanding that container networking is not just a technical implementation challenge but a foundational aspect of modern application architecture that requires ongoing attention and optimization. Teams that embrace this reality and invest in proper tooling, processes, and expertise position themselves for long-term success in containerized environments.
As container orchestration platforms continue to evolve and new networking technologies emerge, the principles we've outlined will remain relevant while the specific implementations adapt to new capabilities and requirements.



