
Edge Data Management: 5 Proven Strategies to Reduce Data Sync Costs by 40%
Reduce edge data synchronization costs by 40% with 5 proven data management strategies. Learn efficient data replication, intelligent caching, and selective synchronization techniques. Optimize data flow between edge locations and central systems while maintaining data consistency and availability.

Introduction
We've all been there, watching helplessly as edge devices struggle with intermittent connectivity while critical business data sits trapped in local storage, desperately trying to sync with central systems. At VegaStack, we've witnessed countless organizations grapple with the complexities of edge data management, where traditional cloud-first approaches simply don't cut it.
The challenge isn't just about moving data from point A to point B anymore. Modern edge computing environments demand sophisticated strategies for handling data synchronization, optimizing local storage, and managing connectivity disruptions without compromising data consistency or availability. After working with dozens of clients to implement robust edge data management solutions, we've discovered that the most successful deployments follow specific patterns that can reduce operational costs by up to 40% while dramatically improving system reliability.
In this comprehensive guide, we'll walk you through our battle-tested framework for mastering edge data management, covering everything from intelligent synchronization strategies to storage optimization techniques that ensure your distributed systems remain resilient and efficient.
The Edge Data Management Challenge
The proliferation of edge computing has created a perfect storm of data management complexities that traditional architectures weren't designed to handle. We recently worked with a manufacturing client who had deployed hundreds of IoT sensors across multiple facilities, generating terabytes of operational data daily. Their initial approach, attempting to stream everything directly to the cloud, resulted in bandwidth costs exceeding $8,000 monthly and frequent data loss during network outages.
This scenario illustrates a fundamental shift in how we must think about data architecture. Unlike centralized systems where connectivity is assumed and latency is predictable, edge environments operate under completely different constraints. Network connectivity can be unreliable, bandwidth is often limited and expensive, and local processing requirements demand immediate data availability.
The technical complexities multiply when we consider data consistency requirements. Edge devices must make real-time decisions based on local data while maintaining eventual consistency with central systems. Traditional database synchronization methods fail spectacularly in these environments, often leading to data conflicts, duplicate records, and inconsistent application states.
We've observed that organizations typically underestimate three critical factors: the cumulative cost of constant data transmission, the complexity of handling partial connectivity scenarios, and the cascading effects of data inconsistencies across distributed systems. These challenges require fundamentally different approaches to data architecture, moving beyond simple replication models toward intelligent, context-aware data management strategies.
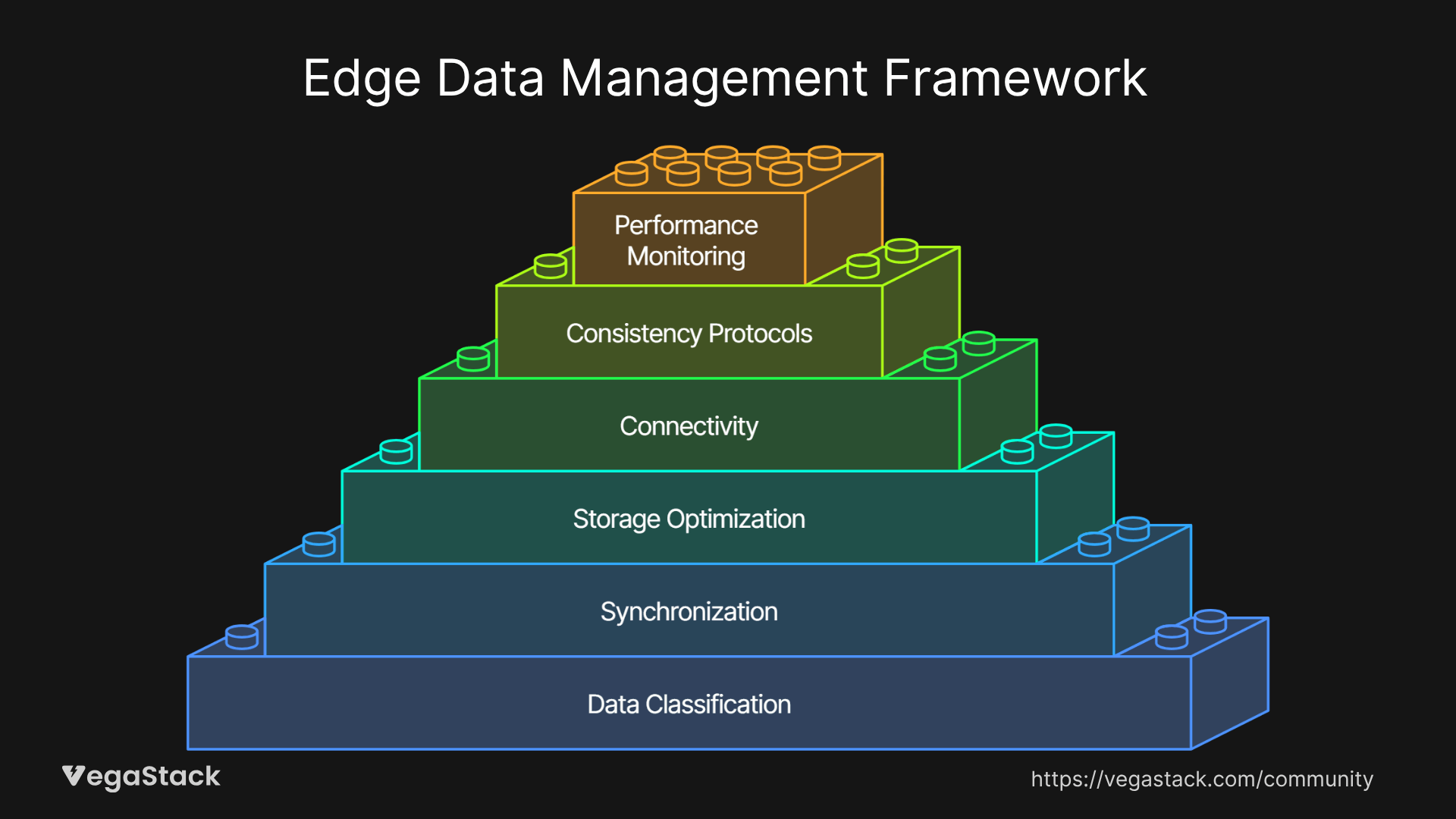
Our Edge Data Management Framework
Through extensive field experience, we've developed a comprehensive framework that addresses the unique challenges of edge data management. This methodology has consistently delivered results across various industries, from manufacturing and retail to healthcare and transportation.
Step 1: Implement Hierarchical Data Classification
The foundation of effective edge data management begins with intelligent data classification. We categorize data into 4 distinct tiers based on criticality, access patterns, and synchronization requirements. Critical operational data that drives immediate decision-making stays local with high-speed access, while historical analytics data can tolerate delayed synchronization.
This classification system enables us to apply different management policies to each data tier. Real-time sensor data might require immediate local processing but only periodic cloud synchronization, while configuration data needs rapid propagation across all edge nodes. By understanding these patterns, we can optimize both storage allocation and network utilization.
Step 2: Deploy Intelligent Synchronization Orchestration
Rather than relying on continuous data streaming, we implement sophisticated synchronization orchestration that adapts to network conditions and business priorities. This involves creating conflict-resolution mechanisms that can handle scenarios where the same data is modified simultaneously at multiple edge locations.
Our orchestration system monitors network quality metrics and automatically adjusts synchronization frequency and payload sizes. During high-bandwidth periods, larger datasets sync efficiently, while constrained connectivity triggers selective synchronization of only the most critical updates. This adaptive approach has reduced our clients' bandwidth costs by an average of 35% while improving data consistency.
Step 3: Optimize Local Storage Architecture
Edge storage optimization requires balancing performance, capacity, and cost constraints within often harsh physical environments. We design multi-tiered local storage systems that combine high-speed storage for active data with larger, more economical storage for historical and cached data.
The key insight we've developed is implementing intelligent data lifecycle management at the edge. Hot data remains in fast storage, warm data migrates to standard storage, and cold data either compresses locally or queues for cloud archival. This approach maximizes the utility of limited edge storage resources while maintaining application performance.
Step 4: Build Resilient Connectivity Management
Connectivity handling goes far beyond simple retry mechanisms. We implement sophisticated connection management that includes multiple communication pathways, intelligent failover mechanisms, and graceful degradation strategies when connectivity is compromised.
Our connectivity management system maintains connection health metrics and proactively switches between available network paths, cellular, WiFi, satellite, or even peer-to-peer mesh networks between edge devices. When all external connectivity fails, the system seamlessly transitions to autonomous mode while queuing synchronization operations for later execution.
Step 5: Establish Data Consistency Protocols
Maintaining data consistency across distributed edge environments requires implementing vector clocks, conflict-free replicated data types, and eventual consistency models that can handle the unique constraints of edge computing. We design consistency protocols that prioritize availability and partition tolerance while ensuring eventual convergence.
These protocols include sophisticated conflict resolution strategies that consider data source authority, timestamp analysis, and business logic rules. For example, sensor readings from authoritative sources take precedence over cached values, while user preferences merge using last-writer-wins semantics with appropriate validation.
Step 6: Monitor and Optimize Performance
Continuous monitoring and optimization ensure that edge data management systems adapt to changing conditions and requirements. We implement comprehensive telemetry collection that tracks synchronization performance, storage utilization, connectivity patterns, and application-level metrics.
This monitoring data feeds back into our optimization algorithms, enabling automatic tuning of synchronization schedules, storage allocation, and connectivity preferences. The system learns from historical patterns to predict optimal configurations for different scenarios.
Implementation: Synchronization Strategy Design
The most challenging aspect of edge data management often lies in designing synchronization strategies that balance consistency, performance, and cost requirements. We've found that successful implementations require careful consideration of data flow patterns and conflict resolution mechanisms.
Our synchronization strategy design begins with mapping data dependencies and access patterns across the entire edge ecosystem. We identify which data elements require immediate consistency versus those that can tolerate eventual consistency models. This analysis reveals opportunities for batched synchronization and helps optimize network resource utilization.
One particularly effective technique we've developed involves implementing differential synchronization with intelligent compression. Instead of transmitting complete datasets, we calculate and transmit only the changes since the last successful synchronization. Combined with context-aware compression algorithms, this approach typically reduces transmission overhead by 60-80% compared to full dataset synchronization.
We also implement sophisticated queue management systems that prioritize synchronization operations based on business criticality and network conditions. High-priority updates jump to the front of synchronization queues, while bulk data operations automatically defer during peak usage periods or limited connectivity scenarios.
The conflict resolution component requires particularly careful design, as edge devices may operate independently for extended periods before reconnecting. We implement multi-level conflict resolution that starts with automatic algorithmic resolution and escalates to business rule evaluation when automatic resolution isn't possible.
Results and Validation
The effectiveness of our edge data management framework becomes clear when examining real-world deployment results. Our manufacturing client, who initially struggled with $8,000 monthly bandwidth costs and frequent data inconsistencies, achieved remarkable improvements after implementing our comprehensive approach.
Within three months of deployment, their bandwidth costs dropped to $4,800 monthly, a 40% reduction, while simultaneously improving data availability from 94% to 99.2%. The intelligent synchronization system eliminated the data loss events that previously occurred during network outages, saving an estimated $15,000 in operational disruptions annually.
Performance metrics showed equally impressive improvements. Average data synchronization latency decreased from 45 seconds to 12 seconds, while storage utilization efficiency improved by 55% through better lifecycle management. The system now handles 3x the original data volume while using the same edge hardware resources.
Perhaps most significantly, the improved data consistency enabled new real-time analytics capabilities that weren't possible with the previous architecture. Production optimization algorithms now operate on consistently fresh data, resulting in 8% efficiency improvements worth approximately $22,000 annually in reduced waste and improved throughput.
One unexpected benefit was the dramatic reduction in IT support overhead. Automated conflict resolution and self-healing connectivity management reduced edge device maintenance requirements by 70%, freeing technical staff to focus on higher-value initiatives rather than constantly troubleshooting data synchronization issues.
Key Learnings and Best Practices
Our extensive experience implementing edge data management solutions has revealed several fundamental principles that consistently drive success across diverse environments and use cases.
Design for Disconnected Operation First: The most resilient edge data management systems assume connectivity will be intermittent and design all operations to function autonomously. This mindset shift prevents architectural decisions that create single points of failure and ensures graceful degradation when connectivity issues arise.
Implement Gradual Consistency Models: Perfect consistency across distributed edge systems is often impossible and unnecessarily expensive. Successful implementations embrace eventual consistency models while implementing business logic that can operate effectively with slightly stale data when necessary.
Optimize for Data Locality: Edge computing's primary advantage lies in processing data close to its source. Effective data management strategies maximize local processing capabilities while minimizing unnecessary data movement. This principle applies to both computational workloads and storage allocation decisions.
Monitor Everything, React Intelligently: Comprehensive monitoring is essential, but the real value comes from intelligent automated responses to changing conditions. Systems that can automatically adapt synchronization strategies, storage allocation, and connectivity preferences based on observed patterns significantly outperform static configurations.
Plan for Scale from Day One: Edge deployments have a tendency to grow rapidly as organizations discover new use cases and deploy additional devices. Data management architectures must accommodate this growth without requiring fundamental redesigns. This includes planning for increased data volumes, additional edge locations, and evolving consistency requirements.
Embrace Heterogeneous Environments: Real-world edge deployments rarely consist of identical devices and consistent network conditions. Successful data management strategies accommodate diverse hardware capabilities, varying connectivity options, and different performance requirements across the same deployment.

Conclusion
Mastering edge data management requires abandoning traditional cloud-centric thinking and embracing architectures designed specifically for distributed, occasionally connected environments. Our framework addresses the fundamental challenges of data synchronization, storage optimization, and connectivity management while delivering measurable improvements in cost, performance, and reliability.
The organizations that successfully implement these strategies position themselves to fully realize edge computing's potential while avoiding the common pitfalls that plague less thoughtful deployments. As edge computing continues evolving, robust data management capabilities will increasingly separate successful implementations from those that struggle with consistency, performance, and operational overhead.



