
How to Fix Distributed Transaction Failures in Microservices
Learn how to handle distributed transaction failures in microservices architectures. This guide covers proven patterns like Saga, two-phase commit, and event sourcing. Get practical solutions for maintaining data consistency across services and recovering from transaction failures effectively.

Direct Answer
Replace traditional distributed transactions with the saga pattern. Break your global transaction into local transactions with compensating actions, use event-driven coordination, and implement transactional outbox patterns. This eliminates 2PC blocking issues while maintaining data consistency across microservices. Most teams see 90%+ success rates within 2-4 weeks of implementation.
Introduction
That uneasy feeling when your order processing system only partially completes, with payment going through but inventory not updating, happens because distributed transactions across microservices are inherently unreliable. Many others face the same challenge.
The reality is that traditional ACID transactions don't work in distributed microservices architectures. When each service owns its database and communicates asynchronously, achieving strict consistency becomes nearly impossible. Two-phase commit protocols create bottlenecks and single points of failure that destroy system reliability.
We'll walk through why this happens and show you the proven saga pattern approach that leading companies use to solve distributed transaction management. This solution maintains data consistency without the headaches of global locking mechanisms.
Problem Context & Symptoms
When This Problem Occurs
Distributed transaction failures typically surface during multi-service workflows like order processing, payment handling, or inventory management. Each microservice maintains its own database, but business operations require coordinated changes across multiple services simultaneously.
The issue becomes critical in cloud-native environments using Kubernetes, event-driven architectures with Kafka, and modern CI/CD pipelines. Teams frequently encounter this when migrating from monolithic applications or scaling existing microservices.
Common Symptoms and Error Messages
You'll notice several warning signs when distributed transactions start failing:
- Partial commits where some services succeed while others fail
- Data inconsistencies appearing across service boundaries
- Transaction timeout errors during 2PC coordination phases
- Deadlock warnings in database logs
- Increased latency during cross-service operations
- Race conditions during system scaling or deployment rollouts
The logs often show incomplete transaction states, failed rollback operations, or services stuck waiting for coordinator responses that never arrive.
Why This Happens
The root issue stems from the distributed systems problem known as the CAP theorem. Microservices architectures prioritize availability and partition tolerance, making strict consistency guarantees impossible during network failures or service outages.
When services communicate asynchronously through message queues or HTTP calls, you lose the atomicity guarantees that single-database transactions provide. Network partitions can leave transactions in limbo, and service failures during commit phases create permanent inconsistencies.
Root Cause Analysis
Technical Explanation
The fundamental problem lies in applying monolithic transaction concepts to distributed systems. Traditional two-phase commit protocols require all participating services to remain available and responsive throughout the entire transaction lifecycle.
In microservices environments, this creates multiple failure points. If any service becomes unavailable during the commit phase, the entire transaction blocks indefinitely. Network latency amplifies these issues, causing cascading timeouts across dependent services.
Each microservice's independent database makes global ACID properties unattainable. Services can't coordinate commits atomically when they don't share transactional resources, and message-based communication introduces ordering and delivery guarantees that break isolation requirements.
Common Trigger Scenarios
Several situations commonly trigger distributed transaction failures:
- Deploying service updates during active cross-service transactions
- Network partitions between microservices and their databases
- Database schema migrations affecting transaction boundaries
- Auto-scaling events that disrupt coordinator service availability
- Circuit breaker activations during high-load periods
These scenarios expose the brittle nature of distributed coordination protocols and highlight why traditional transaction management approaches fail in microservices architectures.
Why Standard Solutions Don't Work
Many teams initially attempt to solve this with tighter coupling or synchronous communication patterns. However, this approach destroys the scalability and resilience benefits that microservices provide.
2-phase commit protocols seem like an obvious solution but introduce blocking behavior that makes systems less reliable, not more. When coordinator services fail, participating services remain locked indefinitely, creating system-wide availability issues.
The assumption that you can maintain strict consistency across distributed services ignores the fundamental trade-offs inherent in distributed systems design.
Step-by-Step Solution
Prerequisites and Preparation
Before implementing saga-based transaction management, ensure you have:
- Administrative access to modify microservices and their databases
- Complete database backups and configuration snapshots
- A workflow orchestration framework like Temporal or Camunda installed
- Messaging infrastructure capable of reliable event delivery
- Monitoring tools configured for transaction state tracking
Validate that all services support idempotent operations and can emit domain events reliably. Test your backup and rollback procedures in a staging environment first.
Implementation Procedure
Step 1: Map Your Transaction Boundaries Identify all business transactions that span multiple microservices. Document the current flow and determine which operations must succeed together from a business perspective.
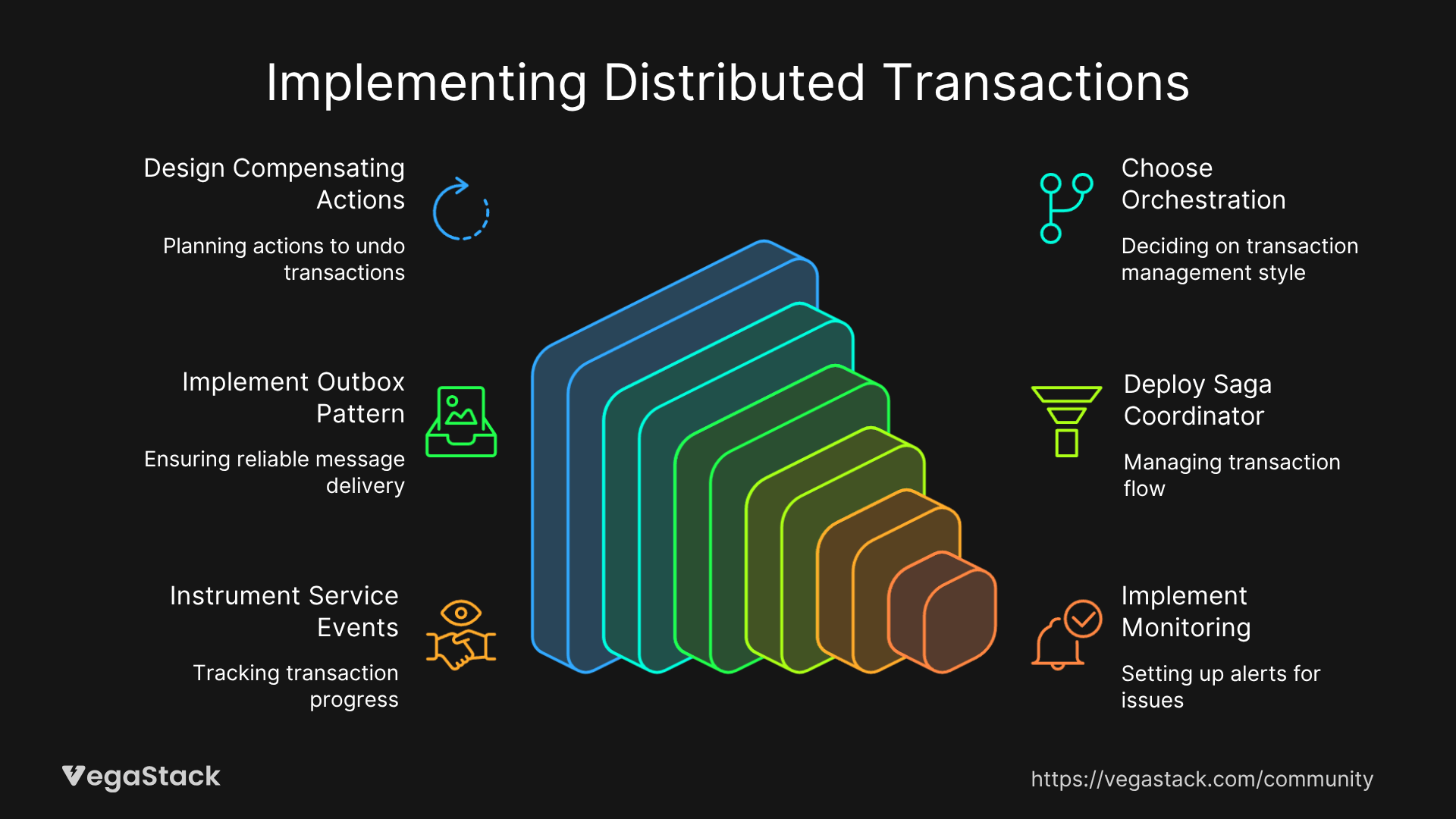
Step 2: Design Compensating Actions For each local transaction step, design a corresponding compensation action that can undo the operation's effects. These compensations must be idempotent and reliably executable.
Step 3: Choose Orchestration vs. Choreography Decide between saga orchestration (centralized coordinator) or choreography (event-driven coordination). Orchestration provides better observability, while choreography offers higher resilience.
Step 4: Implement the Transactional Outbox Pattern Configure each service to store domain events in the same database transaction as business data. Use a separate process to reliably publish these events to your message broker.
Step 5: Deploy the Saga Coordinator Set up your chosen workflow engine to manage saga execution. Configure it to handle retries, timeouts, and compensation triggers based on your business requirements.
Step 6: Instrument Service Events Modify each participating service to emit success and failure events that the saga coordinator can consume. Ensure these events contain sufficient context for compensation decisions.
Step 7: Implement Monitoring and Alerting Configure monitoring for saga execution states, compensation triggers, and transaction success rates. Set up alerts for unusual patterns or prolonged transaction failures.
Step 8: Test Failure Scenarios Use chaos engineering techniques to validate that compensations execute correctly during various failure modes. Test network partitions, service outages, and database failures.
Validation and Testing
Verify your implementation by running integration tests that simulate partial failures at each transaction step. Monitor event delivery, compensation execution, and final consistency achievement.
Load test the saga coordinator to ensure it can handle your expected transaction volume. Measure the time to consistency and compare it with your business requirements.
Troubleshooting Common Issues
| Issue | Symptoms | Solution |
|---|---|---|
| Lost Compensation Events | Data remains inconsistent after failures | Implement event store with replay capabilities |
| Duplicate Compensations | Same compensation executes multiple times | Ensure all compensating actions are idempotent |
| Saga State Loss | Coordinator loses track of in-flight transactions | Use persistent saga state storage with backups |
| Event Ordering Issues | Compensations execute before business operations | Implement event versioning and ordering guarantees |
| Timeout Handling | Sagas hang indefinitely waiting for responses | Configure appropriate timeouts and retry policies |
Edge Cases and Special Scenarios
Legacy system integration requires adapter services that can translate between saga events and traditional transaction boundaries. Design these adapters to handle both successful operations and compensation scenarios.
High-throughput environments may need horizontally scalable saga coordinators. Consider partitioning strategies based on business domains or customer segments to distribute load effectively.
Multi-tenant systems require careful isolation of saga state and compensation logic. Ensure that tenant boundaries are respected throughout the entire transaction lifecycle.
When Solutions Don't Work
If saga implementation doesn't resolve your consistency issues, check for:
- Missing or incorrect compensating transaction logic
- Event delivery failures between services
- Insufficient monitoring of saga execution states
- Network connectivity issues affecting coordination
Use distributed tracing to follow transaction flows and identify where the breakdown occurs. Consider simplifying your saga design or reducing the number of participating services if complexity becomes unmanageable.
Prevention Strategies
Best Practices for Avoiding Recurrence
Design new microservices with eventual consistency in mind from the beginning. Avoid creating transaction boundaries that span multiple services unless absolutely necessary for business requirements.
Implement comprehensive integration testing that validates saga behavior under various failure conditions. Include these tests in your CI/CD pipeline to catch regressions early.
Train your development teams on distributed transaction patterns and the trade-offs between consistency and availability. Establish clear guidelines for when to use sagas versus local transactions.
Monitoring and Alerting Setup
Configure metrics collection for saga execution times, compensation rates, and final consistency delays. Set up dashboards that provide visibility into transaction health across your microservices ecosystem.
Implement alerts for abnormal compensation patterns, saga timeouts, and consistency violations. These early warning systems help you identify issues before they impact business operations.
Long-term Optimization
Regularly review your saga designs as business requirements evolve. Look for opportunities to reduce transaction scope or simplify compensation logic through service boundary adjustments.
Consider upgrading to newer workflow orchestration platforms that provide better tooling for saga management and observability. Invest in automation for saga deployment and configuration management.

Related Issues & Extended Solutions
Connected Problems
Event ordering issues often surface alongside saga implementation. Address these through event versioning and careful dependency management between saga steps.
Service discovery and load balancing configurations may need adjustment to ensure saga coordinators can reliably communicate with all participating services during transaction execution.
Performance optimization becomes critical as saga overhead can impact system throughput. Consider async processing patterns and event batching to minimize coordination costs.
Advanced Techniques
Event sourcing provides an alternative approach that naturally supports saga patterns through immutable event streams. Consider this architecture for systems requiring detailed audit trails.
CQRS (Command Query Responsibility Segregation) can simplify saga design by separating write operations from read model updates, reducing the complexity of maintaining consistency across multiple data projections.
Conclusion & Next Steps
Distributed transaction failures in microservices stem from fundamental architectural mismatches between traditional ACID guarantees and distributed system realities. The saga pattern provides a proven solution that maintains business consistency without sacrificing system reliability.
Start by identifying your most critical cross-service transactions and implementing saga coordination for those flows first. Monitor the results carefully and expand the approach to additional business processes as you gain confidence.
Most teams see significant improvements in system reliability within their first month of saga implementation. The key is starting small, testing thoroughly, and gradually expanding coverage as you refine your approach.
Set up proper monitoring from day one, you'll need visibility into saga execution to troubleshoot issues and optimize performance. The investment in observability pays dividends as your distributed transaction volume grows.
Remember that eventual consistency is not eventual correctness. Design your compensating actions carefully and test them thoroughly to ensure your business invariants remain protected throughout the transaction lifecycle.



