
How to Improve Game Day Exercises for DevOps Teams
Make your game day exercises more effective with proven strategies for DevOps teams. Learn how to design better incident response training, improve team readiness, and create realistic scenarios that actually prepare your team for real outages. Get practical tips that work in any organization.

Quick Solution
Game day improvement requires systematic exercise design with realistic failure scenarios, detailed gap analysis during execution, immediate retrospectives within 48 hours, and iterative refinement cycles. Teams that implement structured game days with surprise elements and blameless post-mortems see 30-40% improvements in Mean Time to Recovery (MTTR) and significantly higher operator confidence during real incidents.
Introduction
Your last game day exercise felt more like theater than real incident response training. Teams fumbled through outdated runbooks, communication broke down, and everyone left wondering if they'd actually be ready for the next production outage. Sound familiar?
Game day exercises are supposed to build confidence and reveal gaps in your incident response capabilities. When done right, they transform how teams handle real emergencies and dramatically reduce downtime. The problem is most organizations run sanitized drills that don't mirror the chaos and pressure of actual incidents.
We'll walk through proven strategies for designing realistic game day scenarios, identifying critical gaps in your response procedures, and building team capabilities that actually translate to better incident outcomes. This approach has helped DevOps teams cut response times in half and eliminate the panic that usually accompanies production failures.
Problem Context & Symptoms
Game day improvement challenges typically surface in complex multi-service environments where dependencies create cascading failure scenarios. You'll see this most often in cloud-native architectures running business-critical services, especially during periods of rapid scaling or after major system changes.
The symptoms are unmistakable: teams take too long to detect and respond to simulated incidents, roles and responsibilities become unclear under pressure, and communication breaks down between different groups. You might notice people referring to outdated documentation or struggling to execute escalation procedures they've never actually practiced.
Common warning signs include overreliance on specific team members who become single points of failure, incomplete monitoring coverage that misses critical alerts, and post-incident reviews that consistently reveal the same coordination problems. Teams often discover their collaboration tools fail under stress or that their alerting systems generate too much noise to identify actual priorities.
The impact goes beyond just longer recovery times. Poor game day performance erodes team confidence and creates anxiety around on-call responsibilities. When real incidents occur, these underlying issues compound into longer outages and more customer impact.
Root Cause Analysis
The technical root causes behind ineffective game day exercises usually trace back to incomplete or outdated incident response processes that don't cover realistic failure modes. Teams build runbooks based on assumptions rather than tested procedures, creating documentation that sounds good but fails under actual conditions.
Tool integration problems frequently surface during exercises when monitoring systems don't trigger expected alerts or communication platforms can't handle the coordination load. These gaps often exist because teams configure systems in isolation without testing end-to-end workflows under stress conditions.
Human factors play an equally important role. Teams that never practice incident response under realistic pressure can't develop the muscle memory needed for effective coordination. The cognitive load of managing complex incidents while learning procedures in real-time overwhelms even experienced engineers.
Standard solutions fail because they focus on documentation and tooling without addressing the coordination and decision-making aspects of incident response. Running sanitized exercises without surprise elements or time pressure doesn't build the resilience teams need for actual emergencies. Many organizations also skip the critical retrospective phase where real learning happens.
Environmental factors compound these issues. System architecture changes, recent deployments, and evolving team structures create moving targets that static procedures can't address. Teams need dynamic approaches that adapt to their current reality rather than theoretical best practices.
Step-by-Step Solution
Prerequisites and Preparation
Start by setting up staging environments that mirror production as closely as possible. You'll need administrative access to trigger controlled failures using tools like AWS Fault Injection Simulator or custom scripts. Prepare dedicated communication channels for the exercise and ensure all monitoring and alerting systems function in your test environment.
Document your current incident response procedures and create backup copies of all configurations before beginning. Inform stakeholders about the game day window without revealing specific scenario details, this maintains the surprise element that makes exercises realistic.
Exercise Design and Execution
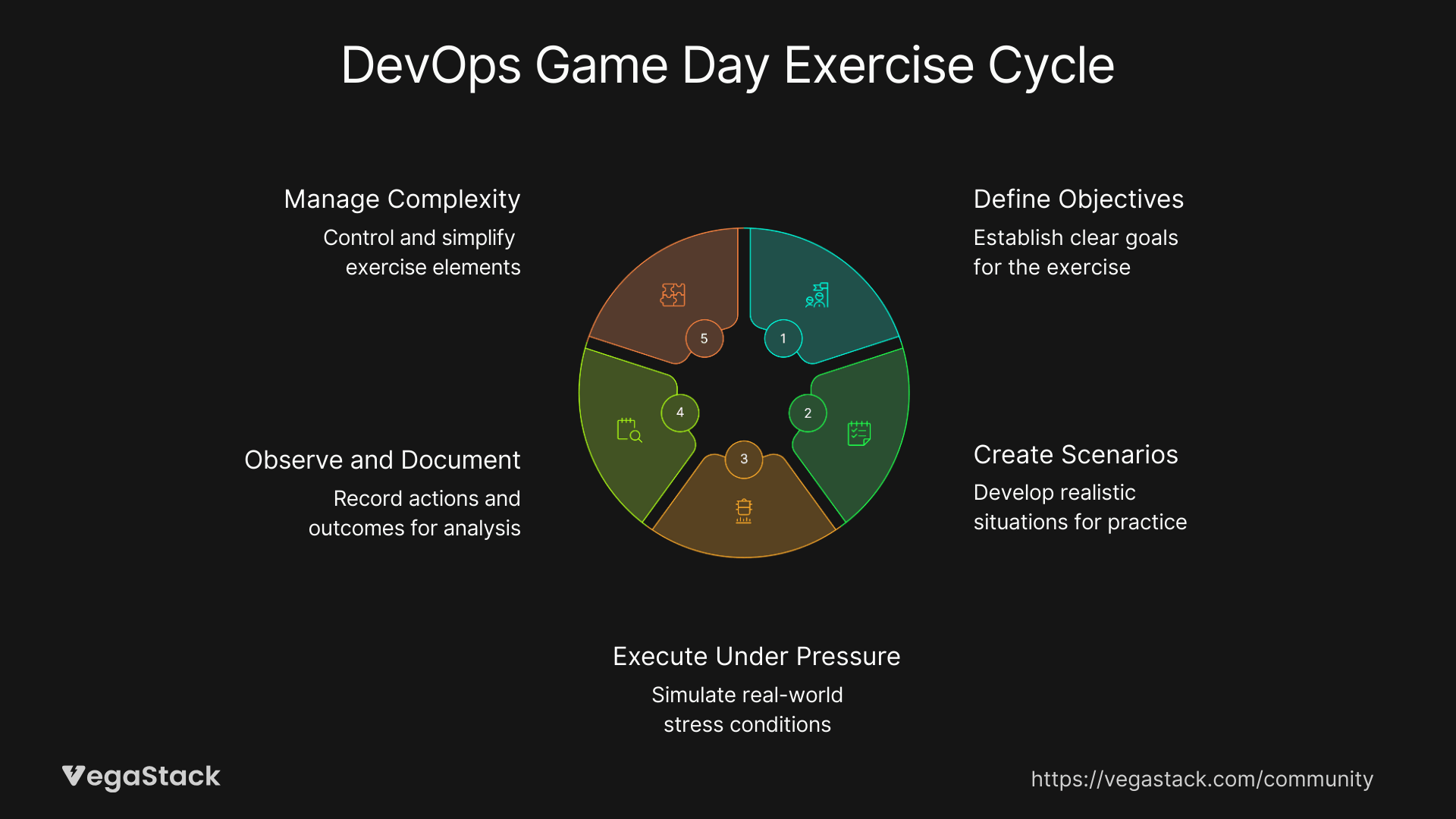
Step 1: Define Clear Objectives
Establish specific goals for what you want to test and improve. Focus on known risk areas like database failovers, network partitions, or service degradation scenarios. Set measurable success criteria such as detection time, escalation speed, and communication effectiveness.
Step 2: Create Realistic Scenarios
Design failure scenarios that start simple but escalate in complexity. Begin with a single service outage, then add complications like monitoring tool failures or key team member unavailability. The scenarios should reflect your actual risk profile rather than generic disaster recovery situations.
Step 3: Execute with Realistic Pressure
Trigger the initial failure and let teams respond naturally without guidance. Document every action, communication, and tool interaction. Introduce surprise elements progressively, perhaps the primary communication tool goes down or the on-call engineer becomes unreachable.
Step 4: Maintain Observation and Documentation
Assign dedicated observers to track response times, communication patterns, and procedure adherence. Don't intervene unless safety issues arise. The goal is authentic response behavior that reveals actual capabilities and gaps.
Step 5: Manage Exercise Complexity
Add layers of complexity as teams demonstrate competency with basic scenarios. This might include cascading failures, partial service degradation, or external dependencies becoming unavailable. Keep exercises challenging but not overwhelming.
Immediate Gap Identification
During execution, watch for specific failure patterns: delayed incident detection, confusion about roles and responsibilities, ineffective communication between teams, and deviation from established procedures. Document these observations in real-time rather than relying on post-exercise memory.
Pay attention to tool-related gaps like missing alerts, incorrect escalation paths, or integration failures between monitoring and communication systems. Note when teams bypass established procedures or create ad-hoc workarounds during the exercise.
Retrospective and Analysis Process
Conduct the retrospective within 48 hours while details remain fresh. Use a blameless approach that focuses on system and process improvements rather than individual performance. Review the timeline of events, identify decision points where responses could have been faster or more effective, and document specific gaps that need addressing.
Create action items with clear owners and deadlines for each identified improvement. These might include runbook updates, tool configuration changes, or additional training requirements.
Troubleshooting Common Issues
| Problem | Cause | Solution |
|---|---|---|
| Teams don't engage seriously | Lack of psychological safety | Emphasize learning over evaluation, leadership participation |
| Scenarios feel unrealistic | Poor environment setup | Improve staging environment fidelity, add time pressure |
| Communication breaks down | Untested collaboration tools | Include communication failures in scenarios, test backup channels |
| Key people become bottlenecks | Undocumented tribal knowledge | Rotate responsibilities, improve documentation coverage |
| Tools don't work as expected | Integration gaps | Test tool chains end-to-end before exercises |
Edge Cases and Special Scenarios
Legacy environments with limited automation require modified approaches focusing on manual procedures and communication protocols. Highly regulated systems need careful isolation to prevent any impact on compliance or production workloads.
Multi-tenant architectures present unique challenges for scoping failures appropriately. Consider tenant-specific scenarios and cross-tenant impact analysis as part of your exercise design.
When exercises reveal gaps that can't be fixed quickly, prioritize based on risk and impact. Some issues require architectural changes or vendor engagement that takes months to resolve.
Prevention Strategies
Build game day exercises into your regular operational rhythm rather than treating them as one-off events. Quarterly exercises work well for most teams, with monthly focused drills for high-risk areas or after significant system changes.
Maintain living documentation that evolves with your systems and team structure. Assign owners for keeping runbooks current and validate procedures against actual system behavior regularly.
Invest in cross-training so knowledge doesn't concentrate in single individuals. Create rotation schedules that expose different team members to various aspects of incident response.
Establish monitoring coverage that aligns with your actual failure modes rather than generic best practices. Use game day results to identify blind spots and adjust alerting thresholds based on realistic response capabilities.
Long-term Optimization
Track key metrics across multiple game day cycles to measure improvement trends. Focus on response time reduction, procedure adherence rates, and team confidence scores rather than just technical metrics.
Use exercise results to inform architecture decisions and system improvements. If certain failure modes consistently cause problems, consider whether system design changes could reduce their impact or likelihood.
Integrate chaos engineering practices into your development pipeline to catch issues before they require formal game day testing. Small, frequent disruptions build resilience more effectively than periodic large-scale exercises.
Related Issues & Extended Solutions
Game day improvement often reveals broader organizational issues around documentation culture, team communication patterns, and technical debt priorities. Address these systemic problems alongside tactical improvements for lasting results.
Consider implementing advanced techniques like red team exercises where one group actively tries to complicate incident response for another team. This adversarial approach reveals additional gaps that standard exercises might miss.
Expand beyond technical scenarios to include security incidents, compliance events, or vendor service disruptions. Different types of incidents require different response patterns and coordination approaches.
Conclusion & Next Steps
Effective game day improvement transforms incident response from panic-driven firefighting into coordinated problem-solving. The key is creating realistic pressure, maintaining focus on learning rather than evaluation, and following through on identified improvements.
Start with simple scenarios and build complexity gradually as team capabilities improve. Remember that the goal isn't perfect execution during exercises, it's building the skills and confidence needed for real incidents.
Schedule your next game day exercise within the next month, focusing on one specific area of your incident response that needs improvement. Keep it realistic, document everything, and conduct the retrospective while the experience is still fresh. Your production systems and on-call team will thank you when the next real incident hits.



