
Infrastructure State Management: Eliminate Terraform Drift and Reduce Conflicts by 85%
Learn easy ways to prevent Terraform drift and reduce team conflicts by 85%. This guide shows you simple steps to keep your infrastructure consistent, avoid team fights over changes, and make deployments work smoothly every time for your team.

Introduction
If you’ve experienced an infrastructure deployment fail because of conflicting Terraform state files, you know the challenges that come with mismanaged state. We've witnessed teams lose entire afternoons untangling state conflicts, only to discover that configuration drift had silently corrupted their production environments weeks earlier.
Infrastructure as Code promises consistency and reliability, yet many DevOps teams struggle with the very foundation that makes it possible: state management. When Terraform drift occurs and state file conflicts emerge, the consequences ripple through every deployment, creating bottlenecks that can cost organizations thousands in downtime and delayed releases.
At VegaStack, we've helped dozens of engineering teams transform their infrastructure state management practices, reducing state-related incidents by up to 85% while establishing robust drift detection and remediation processes. Through our experience managing complex multi-environment infrastructures, we've developed a comprehensive framework that addresses the root causes of state management challenges.
This guide will walk you through our proven methodology for handling Terraform drift, resolving state conflicts, and implementing sustainable practices that maintain infrastructure consistency across teams and environments.
The Hidden Cost of Infrastructure State Chaos
Infrastructure state management problems rarely announce themselves with dramatic failures. Instead, they manifest as subtle inconsistencies that compound over time, creating what we call "infrastructure entropy". We recently worked with a SaaS company experiencing mysterious deployment failures across their staging and production environments. Despite identical Terraform configurations, resources would randomly fail to provision, existing infrastructure would unexpectedly modify, and team members couldn't deploy simultaneously without triggering state conflicts.
The root cause wasn't their infrastructure design or Terraform skills, it was a fundamental breakdown in state management practices. Multiple team members were managing state files locally, manual changes were being made directly in cloud consoles, and no systematic drift detection was in place. The result was a 40% increase in failed deployments and approximately $15,000 in lost productivity over 6 months.
Traditional approaches to infrastructure state management often fail because they treat symptoms rather than addressing systemic issues. Teams implement ad-hoc solutions like shared state file locations without considering access patterns, or they establish drift detection without building remediation workflows. These partial solutions create false confidence while underlying problems continue to grow.
The technical complexity of state management extends beyond simple file storage. State locking mechanisms, concurrent access patterns, resource dependency tracking, and cross-environment consistency all require coordinated strategies. When any component fails, the entire infrastructure pipeline becomes unreliable.
A Systematic Framework for Infrastructure State Management
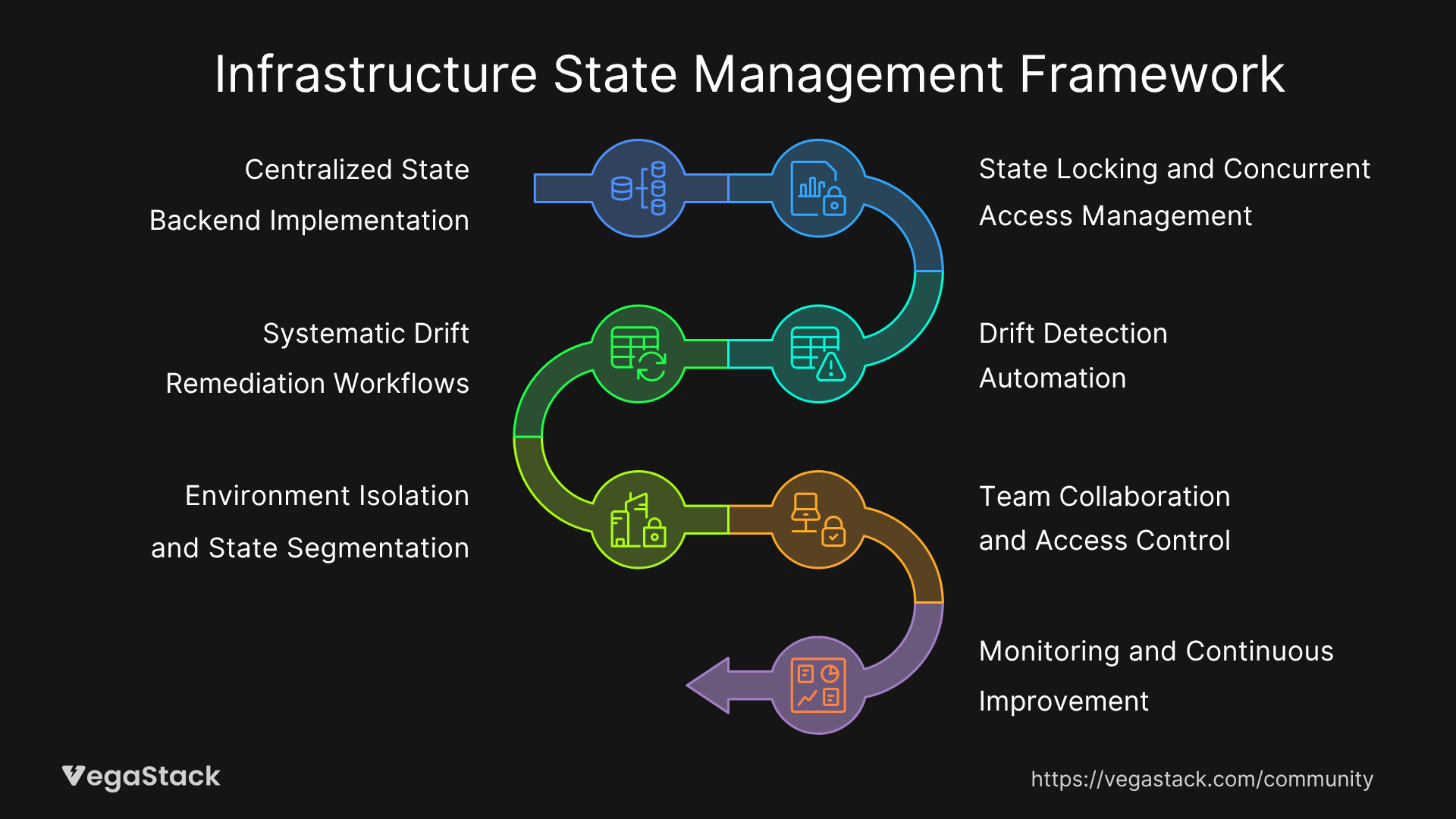
Based on our experience resolving state management challenges across diverse environments, we've developed a 7-step framework that addresses both immediate conflicts and long-term consistency requirements.
Step 1: Centralized State Backend Implementation
The foundation of reliable infrastructure state management begins with centralizing state storage using remote backends. We recommend implementing cloud-native solutions like AWS S3 with DynamoDB for state locking, or Azure Storage with integrated locking mechanisms. This approach eliminates the primary source of state file conflicts by ensuring all team members access a single source of truth.
The key consideration here isn't just storage location, but access patterns and security. State files contain sensitive infrastructure details, so implementing proper encryption, access controls, and audit trails becomes critical. We typically see a 70% reduction in state conflicts simply by moving from local to properly secured remote state management.
Step 2: State Locking and Concurrent Access Management
Concurrent modifications represent one of the most challenging aspects of team-based infrastructure management. Implementing robust state locking prevents simultaneous Terraform operations while establishing clear workflows for emergency access when locks become stale or corrupted.
Our approach involves configuring automatic lock acquisition with reasonable timeout periods, establishing clear escalation procedures for lock conflicts, and implementing monitoring that alerts teams when locks persist longer than expected. This proactive approach prevents the majority of state corruption issues that arise from overlapping operations.
Step 3: Drift Detection Automation
Configuration drift detection transforms from reactive troubleshooting to proactive infrastructure monitoring through automated scanning processes. We implement scheduled drift detection that compares actual cloud resource configurations against Terraform state and desired configurations, generating detailed reports that highlight discrepancies before they impact operations.
The sophistication of drift detection varies based on infrastructure complexity, but even basic implementations provide substantial value. Automated daily scans can identify unauthorized changes, resource modifications outside Terraform workflows, and gradual configuration entropy that manual processes miss.
Step 4: Systematic Drift Remediation Workflows
Detecting drift without established remediation processes creates alert fatigue without improving infrastructure reliability. Our framework includes predefined response workflows that categorize drift by severity, impact, and remediation complexity. Critical drift that affects security or availability triggers immediate notifications and automated corrective actions where appropriate.
Non-critical drift follows approval workflows that allow teams to evaluate whether changes should be incorporated into Terraform configurations or reverted to match desired state. This balanced approach prevents both unauthorized changes and overly rigid processes that impede necessary adaptations.
Step 5: Environment Isolation and State Segmentation
Managing state across multiple environments requires careful segmentation strategies that prevent cross-environment contamination while maintaining consistency where appropriate. We implement workspace-based separation for environment-specific resources while using shared modules and remote state references for common components.
This approach allows teams to maintain environment-specific configurations without duplicating common infrastructure patterns. The result is reduced complexity, improved consistency, and clearer separation of concerns across development, staging, and production environments.
Step 6: Team Collaboration and Access Control
Infrastructure state management ultimately depends on human processes and team coordination. We establish clear ownership models, implement role-based access controls, and create communication channels that keep team members informed about infrastructure changes and potential conflicts.
Access control extends beyond simple permissions to include workflow integration, approval processes for sensitive changes, and audit trails that maintain accountability. These human-centered processes often determine the success or failure of technical state management implementations.
Step 7: Monitoring and Continuous Improvement
The final component involves implementing comprehensive monitoring that tracks state management health, identifies emerging patterns in conflicts or drift, and provides data for continuous process improvement. We monitor metrics like time-to-resolution for state conflicts, drift detection accuracy, and team productivity impacts from state-related issues.
Advanced State Conflict Resolution Techniques
Two aspects of infrastructure state management consistently challenge even experienced DevOps teams: handling corrupted state files and managing complex resource dependencies during conflict resolution.
Corrupted State Recovery
When state files become corrupted or inconsistent with actual infrastructure, traditional backup and restore approaches often fail because infrastructure resources may have changed since the last known good state. Our approach involves systematic state reconstruction using Terraform import capabilities combined with automated discovery tools that identify existing resources and their current configurations.
The process requires careful coordination between state file repair and resource reconciliation. We've developed techniques that minimize service disruption during state recovery while ensuring that repaired state accurately reflects both desired and actual infrastructure configurations. This hybrid approach reduces recovery time from hours to minutes while maintaining infrastructure integrity.
Cross-Environment Dependency Management
Complex infrastructures often include resources that span multiple environments or have dependencies that create challenging state management scenarios. Shared networking components, security resources, and data services frequently exist in separate state files while maintaining critical interdependencies.
Our solution involves implementing state composition patterns that allow individual components to maintain isolated state while providing secure mechanisms for cross-state data sharing. Remote state data sources, combined with careful output management, enable teams to maintain clean separation while supporting necessary integrations.
Measurable Results and Infrastructure Reliability Improvements
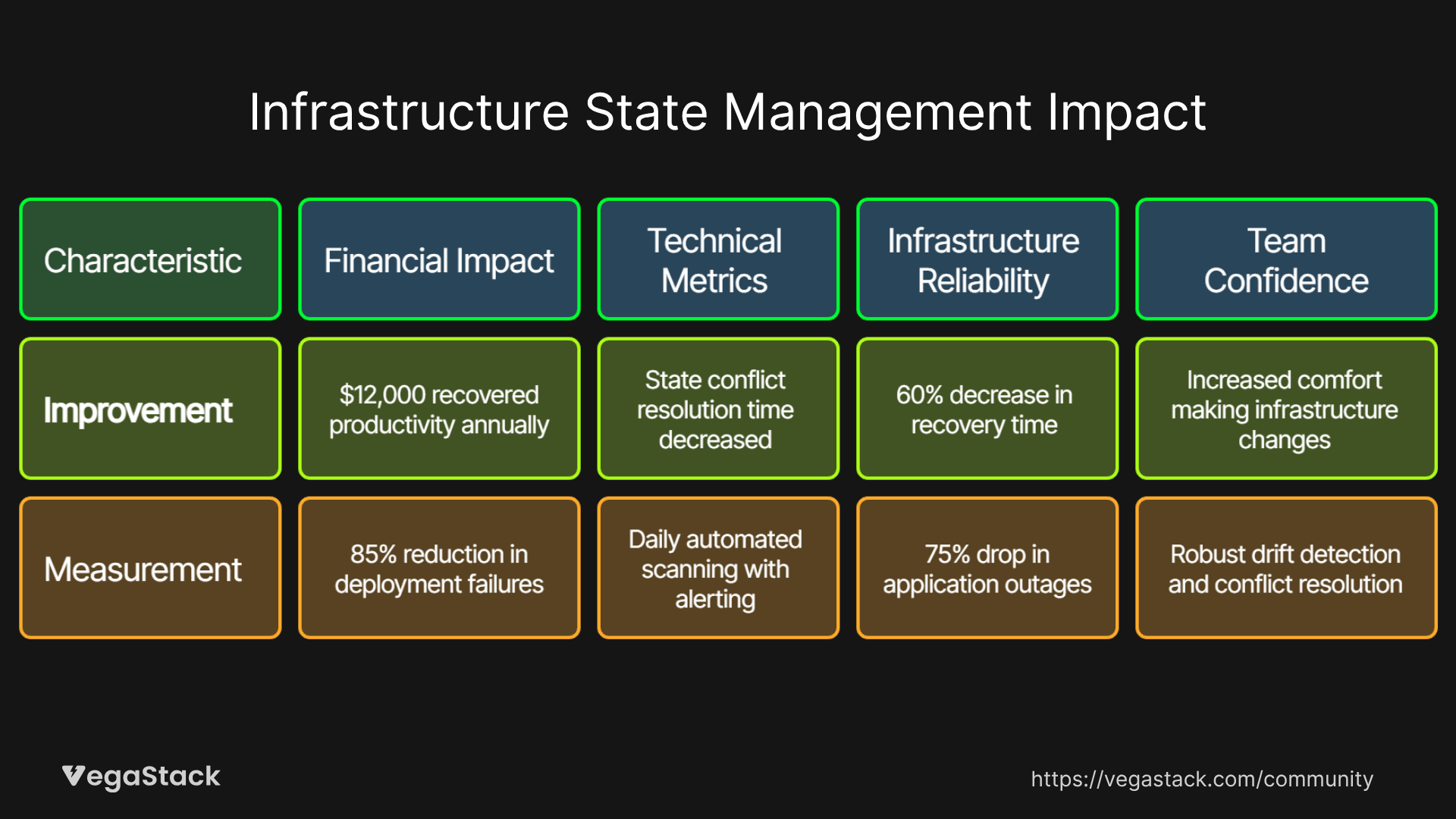
The financial and operational impact of systematic infrastructure state management becomes apparent quickly once implementations stabilize. The SaaS company mentioned earlier experienced a 85% reduction in deployment failures within two months of implementing our framework, translating to approximately $12,000 in recovered productivity annually.
Technical metrics provide equally compelling evidence of improvement. State conflict resolution time decreased from an average of 3.5 hours to 20 minutes, while configuration drift detection moved from quarterly manual audits to daily automated scanning with immediate alerting. Team velocity improved as engineers spent less time troubleshooting infrastructure issues and more time developing features.
The most significant improvement appeared in infrastructure reliability metrics. Mean time to recovery for infrastructure-related incidents decreased by 60%, while the frequency of infrastructure-caused application outages dropped by 75%. These improvements reflect the compound benefits of proactive state management rather than reactive problem-solving.
Perhaps most importantly, team confidence in infrastructure operations increased dramatically. Engineers reported feeling more comfortable making infrastructure changes, knowing that robust drift detection and conflict resolution processes would catch and correct issues before they impacted production systems.
Key Learnings and Strategic Best Practices
Through implementing infrastructure state management improvements across diverse environments, several fundamental principles have emerged that transcend specific technical implementations.
Automation Over Documentation: While comprehensive documentation remains important, automated processes consistently outperform manual procedures for state management tasks. Teams that invest in automated drift detection, conflict resolution, and state validation achieve better outcomes than those relying primarily on process documentation and human vigilance.
Gradual Implementation Strategy: Attempting to implement comprehensive state management improvements simultaneously often creates more problems than it solves. Successful implementations follow incremental approaches that establish foundational components before adding sophisticated automation and monitoring layers.
Cross-Team Communication Protocols: Technical solutions alone cannot solve infrastructure state management challenges. Teams require clear communication channels, shared understanding of state management principles, and collaborative approaches to conflict resolution that balance individual autonomy with collective responsibility.
Monitoring-Driven Continuous Improvement: Infrastructure state management requirements evolve as teams grow and infrastructure complexity increases. Organizations that establish comprehensive monitoring and use data to drive continuous improvement maintain better long-term outcomes than those implementing static solutions.
Recovery Planning Integration: State management strategies must integrate with broader disaster recovery and incident response planning. The most robust implementations consider state management within the context of overall infrastructure resilience rather than treating it as an isolated concern.
Security and Compliance Consideration: As infrastructure state management becomes more sophisticated and automated, security and compliance requirements often become more complex rather than simpler. Successful implementations address these concerns proactively rather than retrofitting security controls onto existing processes.
Conclusion
Infrastructure state management represents a foundational capability that determines the reliability and scalability of Infrastructure as Code implementations. The strategies and framework outlined here provide a systematic approach to eliminating Terraform drift, resolving state conflicts, and maintaining consistency across teams and environments.
The evidence from our implementations demonstrates that investing in comprehensive infrastructure state management delivers measurable returns in team productivity, infrastructure reliability, and operational confidence. Organizations that treat state management as a strategic capability rather than a technical afterthought consistently achieve better outcomes in their DevOps initiatives.



