
Refactoring Strategy: Systematic Code Improvement Without Breaking Features - 7 Proven Steps for Zero-Downtime DevOps
Refactoring doesn’t need to break features or cause downtime. Follow 7 clear steps to restructure code safely, apply smart testing, and roll out improvements gradually. Improve code quality while keeping systems reliable, stable, and fast.

Introduction
We've all been there, staring at a codebase that works perfectly in production but makes every developer cringe when they need to add new features. The technical debt keeps growing, velocity slows down, and everyone knows the code needs improvement. Yet, the fear of breaking critical functionality paralyzes teams from taking action. This is where a systematic refactoring strategy becomes your lifeline.
After implementing refactoring initiatives across dozens of production systems, we've learned that successful code improvement isn't about heroic weekend rewrites or risky big-bang deployments. Instead, it's about developing a disciplined approach that prioritizes systematic code improvement while maintaining absolute system stability. The teams that master this balance typically see 40-60% reduction in bug reports and save thousands of dollars in maintenance costs annually.
In this comprehensive guide, we'll walk you through our tested 7-step framework for refactoring strategy implementation, complete with risk assessment protocols, testing methodologies, and incremental improvement techniques that ensure your features keep working while your code gets better.
The Technical Debt Dilemma: When Good Systems Go Bad
Last month, we worked with a mid-sized e-commerce platform struggling with a classic scenario. Their checkout system processed thousands of transactions daily without major incidents, but adding simple features like promotional codes required weeks of development time. The engineering team estimated they were spending 70% of their cycles working around existing code limitations rather than building new functionality.
The financial impact was staggering, feature delivery timelines had stretched from days to months, costing the company approximately $15,000 per quarter in delayed product launches. More concerning was the growing instability: minor changes increasingly triggered unexpected behaviors in seemingly unrelated system components.
Traditional approaches to this problem typically fail because they treat refactoring as an all-or-nothing proposition. Teams either attempt massive rewrites that introduce significant risk and downtime, or they continue patching around problems until the system becomes unmaintainable. Both strategies ignore the fundamental challenge: how do you improve code quality systematically while maintaining the reliability that production systems demand?
The complexity intensifies when you consider modern DevOps environments where multiple teams deploy changes daily, automated pipelines expect consistent interfaces, and customer-facing features must remain available around the clock.
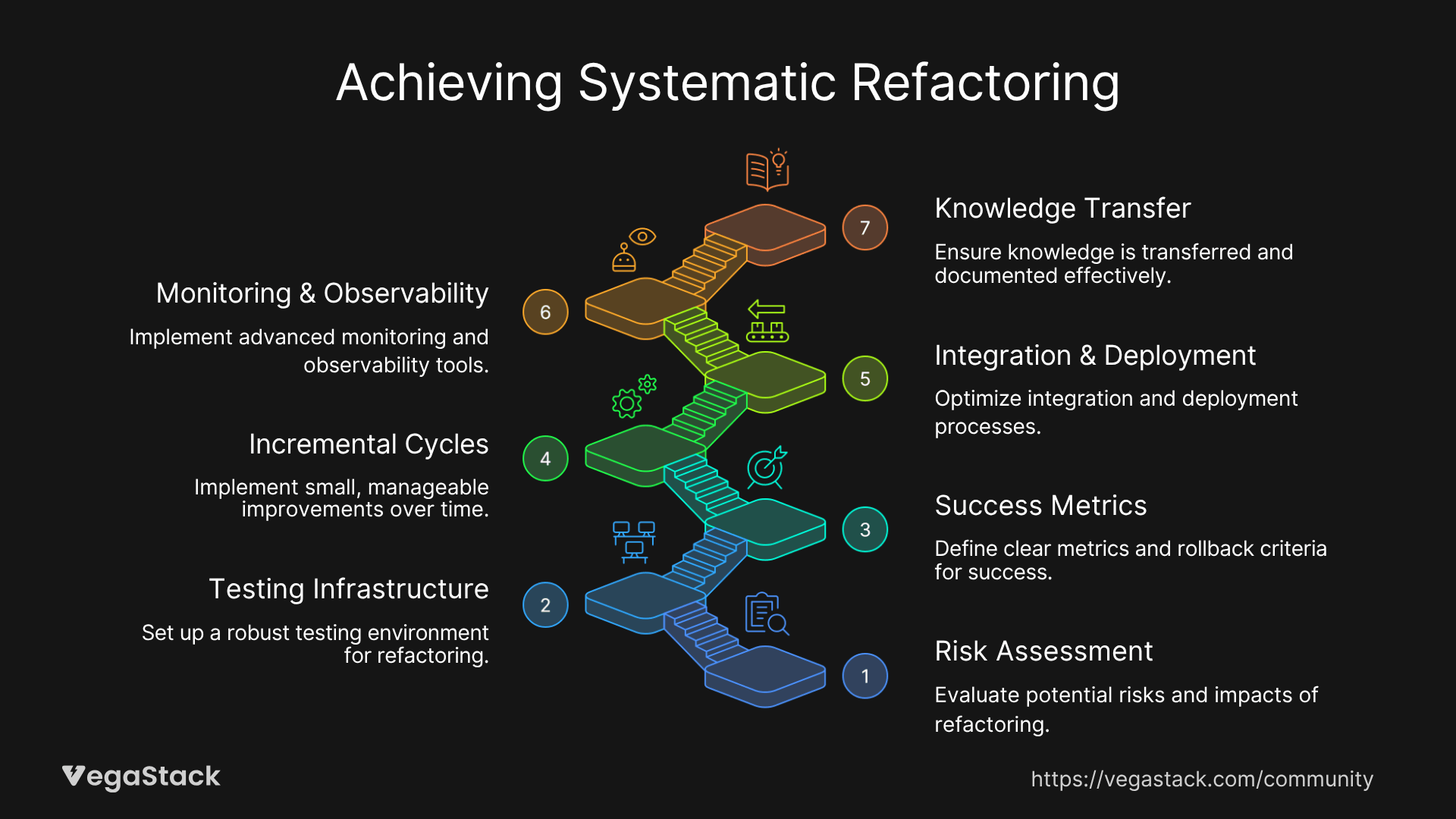
The 7-Step Systematic Refactoring Framework
Step 1: Comprehensive Risk Assessment and Impact Analysis
The foundation of any successful refactoring strategy begins with understanding what you're working with. We start by creating a detailed system map that identifies all components, their interdependencies, and potential failure points. This isn't just about technical architecture, it includes understanding business criticality, user impact zones, and downstream system effects.
Our risk assessment process evaluates each potential refactoring target across multiple dimensions: complexity level, business criticality, change frequency, and blast radius if something goes wrong. We categorize components into high, medium, and low risk categories, which directly influences our approach timeline and testing requirements.
Step 2: Establish Comprehensive Testing Infrastructure
Before touching any production code, we ensure robust testing coverage exists for the target areas. This means implementing multiple testing layers: unit tests for individual component behavior, integration tests for system interactions, and end-to-end tests for critical user journeys. We've learned that attempting incremental refactoring without solid test coverage is like performing surgery without anesthesia, technically possible, but unnecessarily painful.
The testing infrastructure also includes performance benchmarking capabilities. We establish baseline metrics for response times, resource utilization, and throughput before beginning any changes. This data becomes crucial for validating that improvements don't inadvertently introduce performance regressions.
Step 3: Define Clear Success Metrics and Rollback Criteria
Systematic code improvement requires measurable objectives. We define specific, quantifiable goals for each refactoring initiative: reducing cyclomatic complexity by specific percentages, improving test coverage to defined thresholds, or decreasing build times by measurable amounts. Equally important are the failure criteria that trigger immediate rollback procedures.
Step 4: Implement Incremental Improvement Cycles
The heart of our refactoring strategy lies in small, frequent improvements rather than large, risky changes. We break down complex refactoring tasks into incremental steps that can be completed, tested, and deployed independently. Each cycle follows a strict pattern: isolate the change, implement the improvement, validate functionality, measure impact, and document lessons learned.
This approach allows teams to maintain continuous delivery while steadily improving code quality. If any individual change introduces problems, the blast radius remains small and rollback procedures are straightforward.
Step 5: Continuous Integration and Deployment Optimization
Refactoring efforts must integrate seamlessly with existing DevOps pipelines. We enhance continuous integration processes to include additional validation steps for refactored components, implement feature flags to control change exposure, and establish monitoring alerts specific to areas under active improvement.
The deployment strategy emphasizes gradual rollouts with real-time monitoring. We typically deploy refactored components to small user segments initially, gradually expanding coverage as confidence builds. This approach has prevented numerous potential incidents and allowed teams to catch subtle issues before they impact broader user bases.
Step 6: Advanced Monitoring and Observability Implementation
Systematic refactoring requires enhanced observability into system behavior. We implement detailed logging, metrics collection, and distributed tracing for components undergoing improvement. This visibility allows teams to understand the real-world impact of changes and identify optimization opportunities that weren't apparent during development.
The monitoring strategy includes both technical metrics like error rates and response times, and business metrics like conversion rates and user satisfaction scores. This comprehensive view ensures that code improvements translate into measurable business value.
Step 7: Knowledge Transfer and Documentation Protocols
The final step involves capturing and sharing the improvements made during the refactoring process. We document architectural decisions, update system diagrams, and create knowledge transfer sessions for team members. This ensures that the benefits of systematic code improvement extend beyond the immediate changes to improve overall team capability and system understanding.
Implementation: Managing Database Schema Evolution
One of the most challenging aspects of systematic refactoring involves database schema changes, where the risk of breaking existing functionality is particularly high. Our approach to this challenge demonstrates how the framework adapts to complex technical scenarios.
We recently guided a team through refactoring a legacy user management system where the database schema had evolved organically over 5 years. The tables contained redundant columns, inconsistent naming conventions, and missing foreign key constraints that made feature development increasingly difficult.
The solution involved implementing a multi-phase schema evolution strategy. First, we created comprehensive data migration scripts that could run in both forward and reverse directions. Then, we implemented an abstraction layer that allowed the application to work with both old and new schema structures simultaneously. This dual-compatibility approach enabled us to migrate data incrementally while maintaining full system functionality.
The process included implementing detailed data validation checks at each migration step, real-time monitoring of query performance during transitions, and automated rollback procedures if any anomalies were detected. We also established communication protocols with stakeholder teams to coordinate the changes across multiple services that depended on the database structures.
Results and Validation: Measurable Improvements
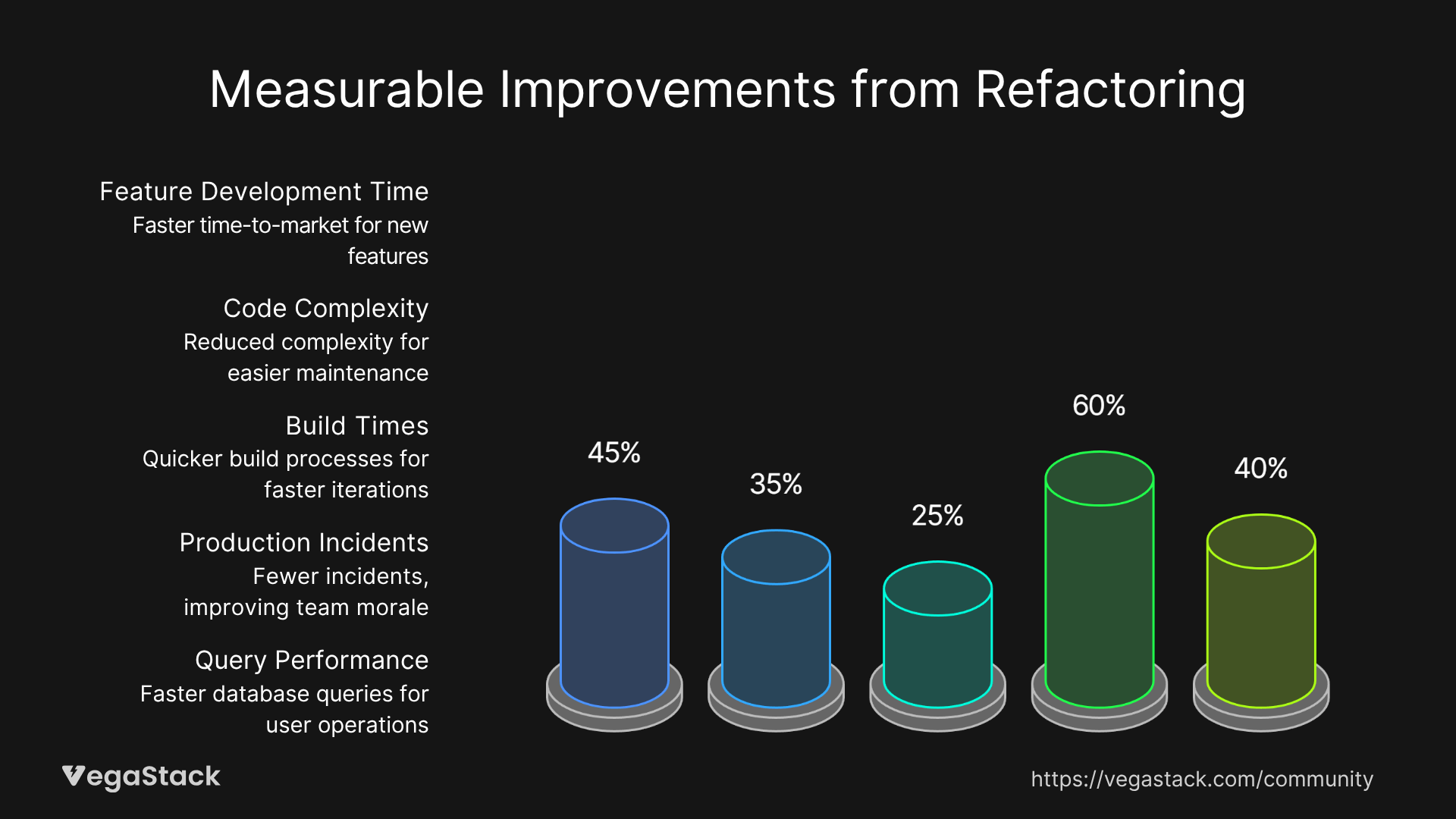
The systematic refactoring approach consistently delivers measurable improvements across multiple dimensions. In the e-commerce platform case study mentioned earlier, the team achieved a 45% reduction in feature development time within three months of implementing our framework. This translated to approximately $12,000 in quarterly savings through faster time-to-market for new features.
Technical metrics showed equally impressive improvements: code complexity scores decreased by 35%, test coverage increased from 60% to 85%, and build times improved by 25%. Perhaps most importantly, production incidents related to the refactored components decreased by 60%, significantly reducing on-call burden and improving team morale.
The database schema refactoring project resulted in 40% faster query performance for user-related operations and eliminated the need for several workaround solutions that had accumulated over time. The improved data consistency also enabled new analytics capabilities that provided additional business value.
User-facing metrics remained stable throughout all refactoring activities, confirming that the systematic approach successfully improved code quality without impacting system functionality. Customer satisfaction scores actually improved slightly, likely due to faster feature delivery and improved system reliability.
However, it's important to note that these improvements didn't happen overnight. The full benefits became apparent over several months, and some teams initially experienced slightly slower development velocity as they adapted to the new processes and tooling requirements.
Key Learnings and DevOps Best Practices
Through dozens of refactoring initiatives, we've identified several fundamental principles that separate successful systematic code improvement from failed attempts.
Incremental progress beats perfect solutions. Teams that attempt comprehensive refactoring in single efforts consistently struggle with complexity management and risk mitigation. The most successful improvements happen through consistent, small changes that compound over time.
Testing infrastructure is non-negotiable. Every successful refactoring strategy we've implemented included significant investment in automated testing capabilities before beginning code changes. This upfront investment pays dividends throughout the improvement process.
Observability drives decision-making. Teams with comprehensive monitoring and metrics collection make better refactoring decisions and catch problems earlier. The data-driven approach eliminates guesswork and provides objective validation of improvement efforts.
Stakeholder communication prevents surprises. Refactoring activities impact multiple teams and systems. Clear communication about timelines, potential risks, and expected benefits helps maintain organizational support throughout the improvement process.
Rollback procedures are as important as implementation plans. Every refactoring step should include clear criteria for success and failure, with predetermined rollback procedures if things don't go as expected.
Knowledge sharing multiplies impact. The most valuable refactoring initiatives include documentation and knowledge transfer components that help the entire organization learn from the improvement process.
Conclusion
Systematic refactoring strategy transforms the overwhelming challenge of code improvement into a manageable, repeatable process that delivers measurable results without compromising system stability. The core strategy involves adopting incremental improvement methods, conducting detailed risk assessments, and maintaining a strong emphasis on continuous testing and validation.
The teams that master this approach consistently deliver better software faster while reducing technical debt and maintenance overhead. They prove that you don't have to choose between code quality and feature delivery, with the right refactoring strategy, you can achieve both simultaneously.



